Born to be cloud
Creating robust digital systems that flourish in an evolving landscape. Our services, spanning from Cloud to Applications, Data, and AI, are trusted by 150+ customers. Collaborating with our global partners, we transform possibilities into tangible outcomes.







.png)
.png)




.png)











.png)
.png)




.png)













.png)






Experience our services.
We can help to make the move - design, built and migrate to the cloud.
Cloud Migration
Maximise your investment in the cloud and achieve cost-effectiveness, on-demand scalability, unlimited computing, and enhanced security.
Artificial Intelligence/ Machine Learning
Infuse AI & ML into your business to solve complex problems, drive top-line growth, and innovate mission critical applications.

Data & Analytics
Discover the Hidden Gems in Your Data with cloud-native Analytics. Our comprehensive solutions cover data processing, analysis, and visualization.

Generative Artificial Intelligence (GenAI)
Drive measurable business success with GenAI, Where creative solutions lead to tangible outcomes, including improved operational efficiency, enhanced customer satisfactions, and accelerated time-to-market.

.png)
.png)


Ankercloud: Partners with AWS, GCP, and Azure
We excel through partnerships with industry giants like AWS, GCP, and Azure, offering innovative solutions backed by leading cloud technologies.



-p-500.png)
.png)
.png)
.png)
Our Specializations & Expertise

-p-500.png)
SUCCESS STORIES
Our Customers Stories

High Performance Computing using Parallel Cluster, Infrastructure Set-up


gocomo Migrates Social Data Platform to AWS for Performance & Scalability with Ankercloud


Migration a Saas platform from On-Prem to GCP


Benchmarking AWS performance to run environmental simulations over Belgium
.jpg)
Countless Happy Clients and Counting!

"Ankercloud is working as a direct extension of our team. Their strong technical know-how, agile approach, and cross-cloud experience have
accelerated our cloud journey - from DevOps to AIML Development. They are a valuable partner to have."

“It is almost unbelievable how we could build a SaaS solution for Antibody patent analysis at AWS in only a few months, from nothing to 100% up and running. Many thanks to the team at Ankercloud, AWS Rising Star Partner 2023”

"Whatever questions we had, Ankercloud was really proactive about getting us the right person to talk to. Whenever we had an issue, they did a great job of mitigating the impact and the cost and finding us a good solution.”

“Ankercloud has been very helpful and understanding. All interactions have been smooth and enjoyable.”
"Overall, the adoption of cloud infrastructure empowers our research group to propel our scientific pursuits with greater efficiency and effectiveness."
.PNG)
Check out our blog
.png)
Building an Automated Voice Bot with Amazon Connect, Lex V2, and Lambda for Real-Time Customer Interaction
Today we are going to build a completely automated Voice Bot or to set up a call center flow which can provide you with real time conversation by using Amazon connect, Lex V2, DynamoDB, S3 and Lambda Function services available in the amazon console. The voice bot is built in German and below is the entire flow that is followed in this blog.
Advantages of using Lex bot
- Lex enables any developer to build conversational chatbots quickly.
- No deep learning expertise is necessary—to create a bot, you just specify the basic conversation flow in the Amazon Lex console. The ASR (Automatic Speech Recognition) part is internally taken care of lex so we don’t have to worry about that. You seamlessly integrate lambda functions, DynamoDB, Cognito and other services of AWS.
- Compared to other services Amazon Lex is cost effective.
Architecture Diagram
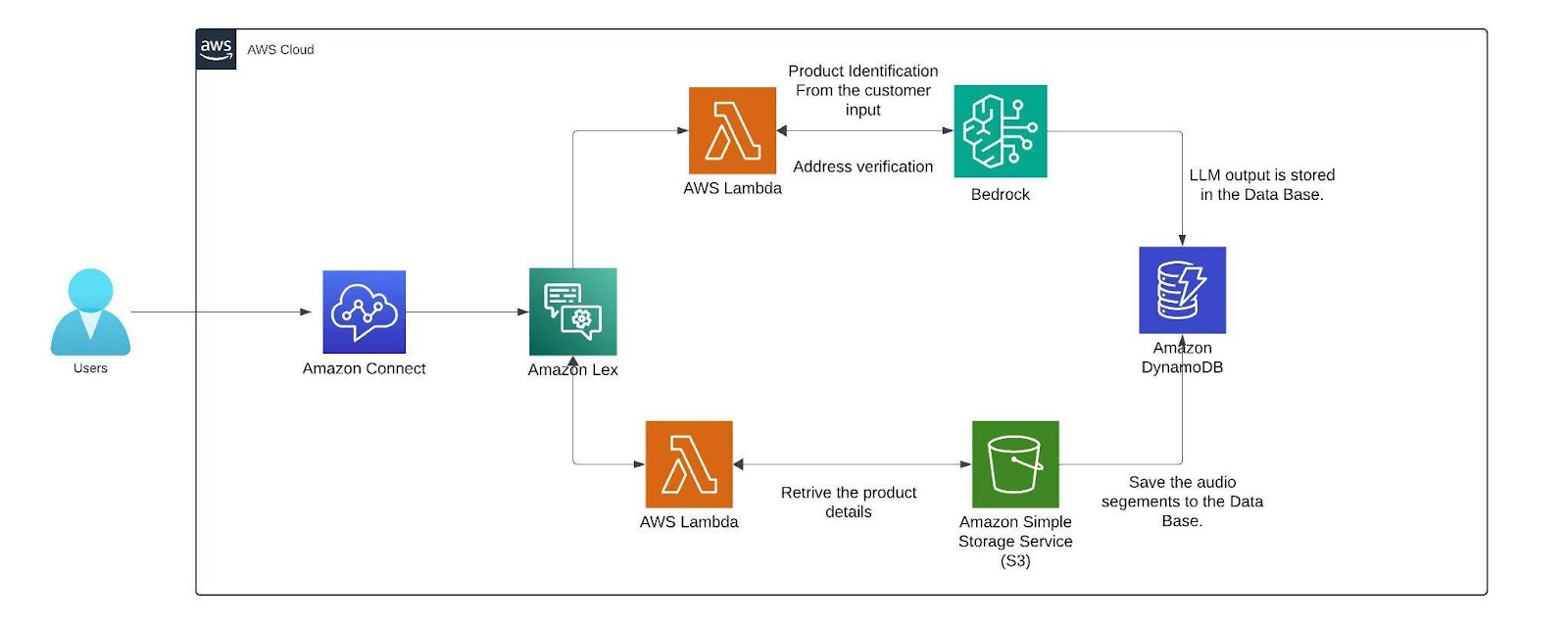
Architecture
Within the AWS environment, Amazon Connect is a useful tool for establishing a call center. It facilitates customer conversations and creates a smooth flow that combines with a German-trained Lex v2 bot. This bot is made to manage a range of client interactions, gathering vital data via slots (certain data points the bot needs) and intents (activities the bot might execute). The lex bot is then attached to a lambda function which gets triggered when the customer responds with a product name if not it directly connects the customer to the human agent for further queries.
The lambda function first finds the product name from the customer input then it is compared with the product's list which we have in the S3 bucket where it has details like price, weight, size, etc.. from an excel sheet (excel sheet) that now contains only two products namely Samsung Galaxy S24 and Apple iPhone 15 with the pricing weight and size of the product. The customer's input is matched with the closest product name in the excel sheet using the fuzzy matching algorithm.
The threshold for this matching of products is set to 60 or more which can be altered based on the need. Only if the customer wants to order, the bot starts collecting customer details like name and other details. The bot has a confirmation block which responds to the customer with what it understood from the customer input(like an evaluation ) if the customer doesn’t confirm it asks for that particular intent again. If you need, we can add the retry logic. Here a max retry of 3 is set to all the customer details just to make sure the bot retrieves the right data from the customers while transcribing from speech to text (ASR).
After retrieving the data from the customer before storing them we can verify the data collected from the customer is valid or not by passing it to the Mixtral 8x7B Instruct v0.1 model here i am using this model because my conversation will be in German and since the mistral model is trained in German and other languages it will be easy for me to process this model is called using the Amazon Bedrock service. We are invoking this model in the lambda function which has a prompt template which describes a set of instructions for example here i am giving instructions like just extract the product name from the callers input. After getting the response from LLM the output is then stored as session attributes in code snippet below along with the original data and the call recordings segments from the s3 bucket.
def update_custom_attribute(event, field_name, field_value):
session_state = event['sessionState']
if 'sessionAttributes' not in session_state:
session_state['sessionAttributes'] = {}
if 'userInfo' not in session_state['sessionAttributes']:
user_info = {}
else:
user_info = json.loads(session_state['sessionAttributes']['userInfo'])
updated_session_state = update_custom_attribute(event, 'name', name_value)
return {
"sessionState": {
"dialogAction": {
"type": "ElicitSlot",
"slotToElicit": "country"
},
"intent": {
"name": "CountryName",
"state": "InProgress",
"slots": {}
},
"sessionAttributes": updated_session_state['sessionAttributes']
},
"messages": [
{
"contentType": "PlainText",
"content": "what is the name of your country?"
}
]
}
Finally the recordings are stored in the dynamo db. with the time as primary key so that each record is unique.
AMAZON CONNECT
This is how the interface of Amazon Connect looks like you can create a new instance by clicking the add an instance button. you can specify the name of the URL connect instance. After creating the instance click the emergency login/access URL(sign in with the user account you created while creating the instance).
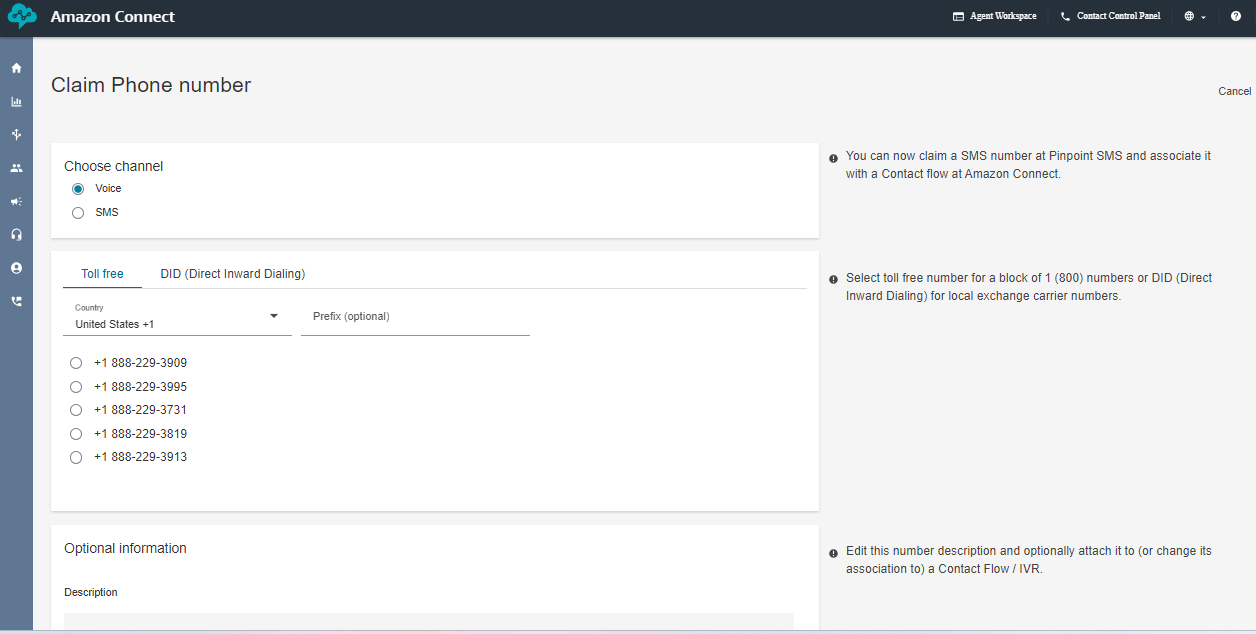
The below image creates the toll free numbers where you select the phone icon and select the phone number and click claim a number then select the voice for voice bot and the country in which you want to create the number for and click the save button remember while you are claiming the number for few countries you need to submit proof of documents refer this document [1] .
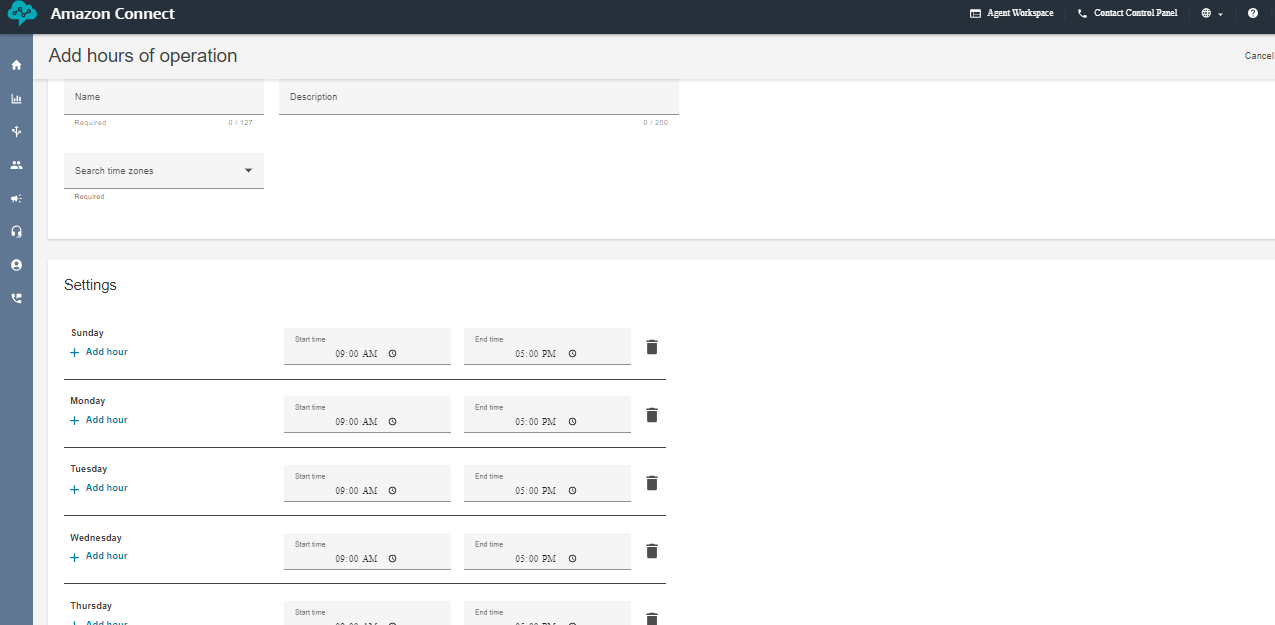
Next, create the working hours from the flow arrow of the console. I have created a 9 A.M to 5 P.M so that i can connect the call to the human agent if the caller has any queries. But if you want your voice bot to be available 24/7 then change the availability or create a new hours of operations.
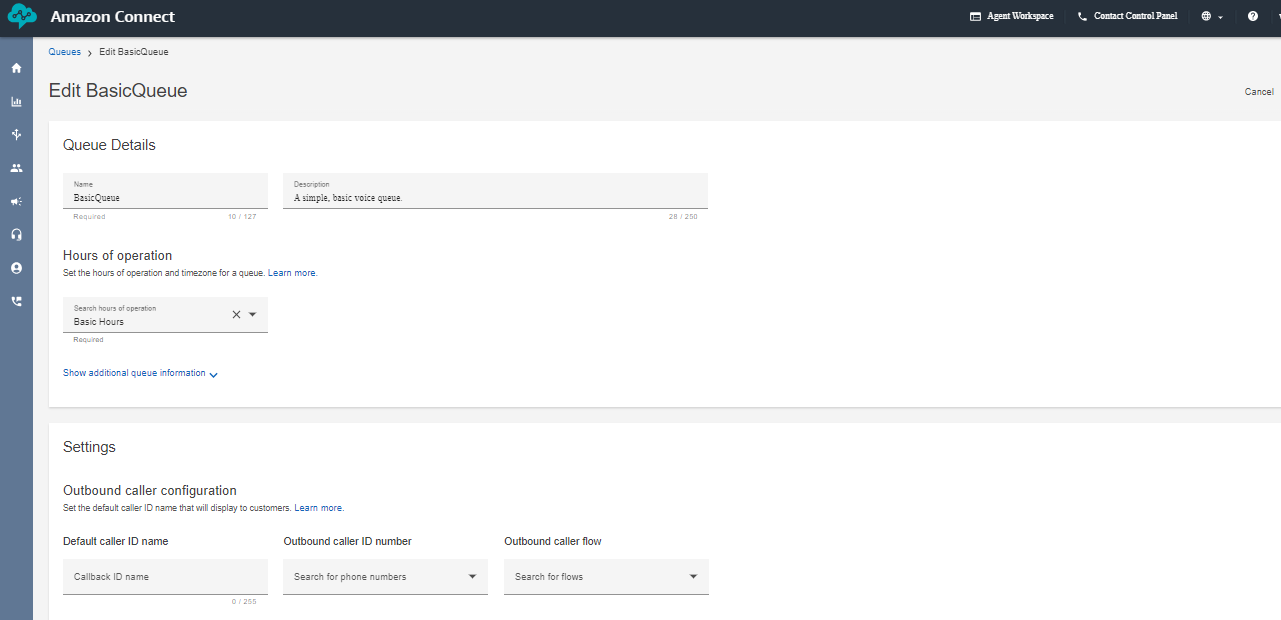
Next create a queue and add the hours of operation in the queue. That's it we are almost done setting up a few things in the Amazon Connect now lets go inside the flows and look how our complete flow looks like.
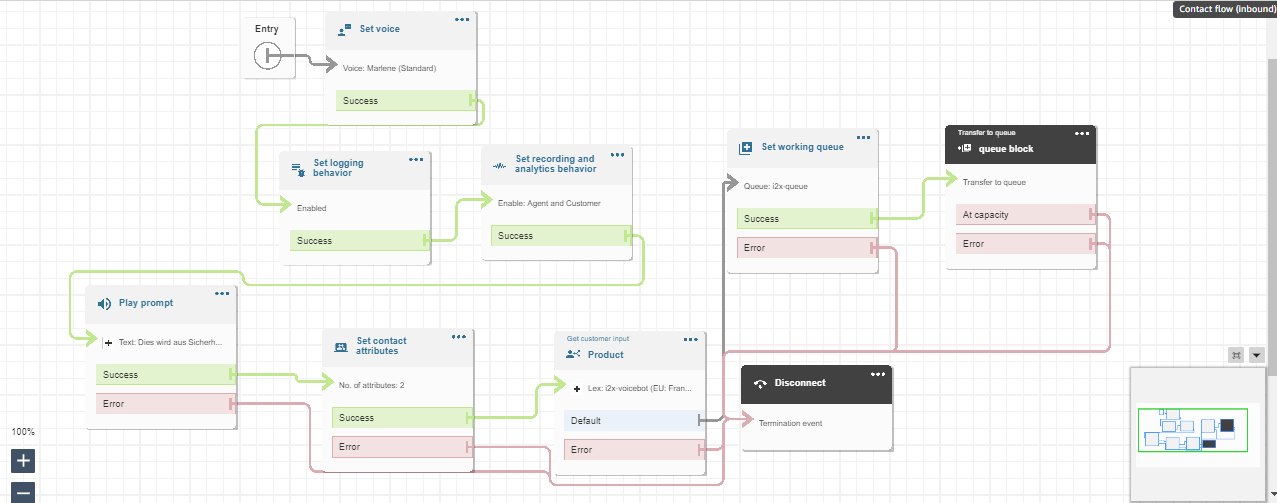
This above diagram is the Amazon Connect Flow where the set voice block is used to set a specific voice. The set logging behavior block and set recording and analytics behavior is used to record the conversation after connecting to the agent. Play prompt is used to respond a simple prompt saying the call is recorded. The set contacts attribute block contains two session attributes one for focusing on the user’s voice rather than the background noise and another is to not barge in when the bot is responding after adding these two session attributes in the connect flow the call is able to pass the flow even when there a certain amount of background noise. The get customer input block is used for connecting the call to the lex bot if the customer wants to connect to the agent the set working queue ensures to connect to the agent. Finally the call is disconnected using the disconnect block.
AMAZON LEX
Next, We can create a bot from scratch by clicking on the create bot icon on the lex console. you can specify the name of the bot with the required IAM permissions and select “no” for the child protection. In the next step choose the language you want your bot to train and select the voice. The intent classification score is set in between 0 to 1. It is similar to a threshold where the bot can classify the customers/user reason for example, if i have multiple intent based on the score it connects to the most likely intent. you can also add multiple languages to train your
bot.
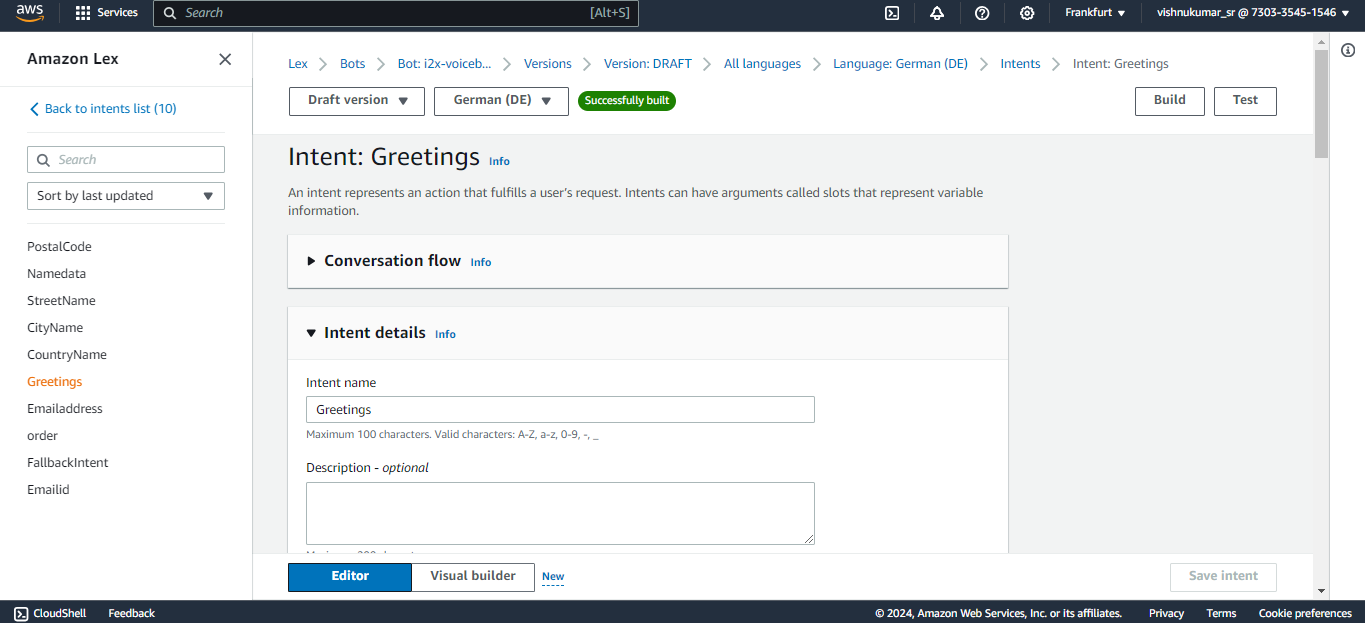
You can create an intent to know the customers/callers need for calling like, Ordering a mobile in our case we expect a product name from the customer like Samsung galaxy or apple iPhone. The sample utterances are used to initiate the conversation with the bot at the very beginning of the conversation for example we can say hi, hello, i want to order, etc. to trigger the intent that you expect your bot to responded based the customer reason. If you have multiple intents like greetings, order, address you connect these intent in a flow one after other in a flow using the go to intent block.
Slots are used to fulfill the intent like for example here the bot needs to know which product the customer wants to order to complete this greetings intent. Likewise you can create slots in a single intents or create separate slots in each intent and connect them in the flow. The confirmation block is used for rechecking the user input like the product name based on the response from the customer (if the customer says “yes” it will go to the next step if “no” then it goes to the previous state and asks the question again).
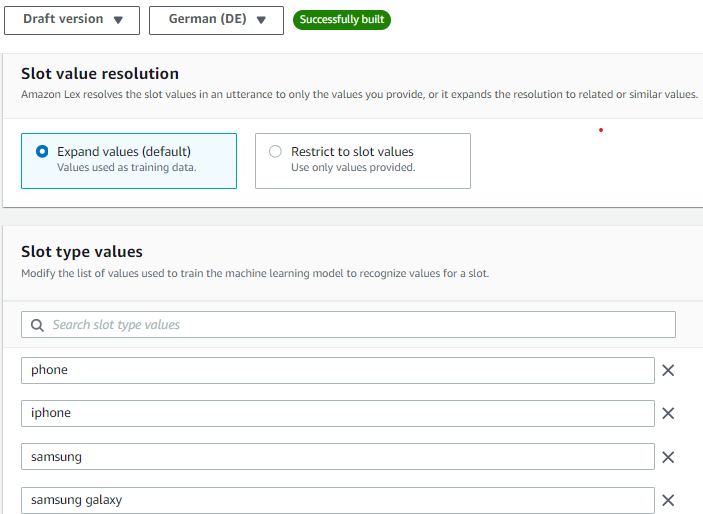
You can improve the accuracy of the lex bot by recognizing what the customer is saying speech recognition (ASR) by creating a custom slot type and training the bot with a few examples of what the customer might say. For example, in our case the customer might say the product names like iPhone, apple iPhone, iPhone 15 etc.. so add few values in the slot utterances which can improve the speech detection. You can create multiple custom slot types like product name, customer name, address, etc..
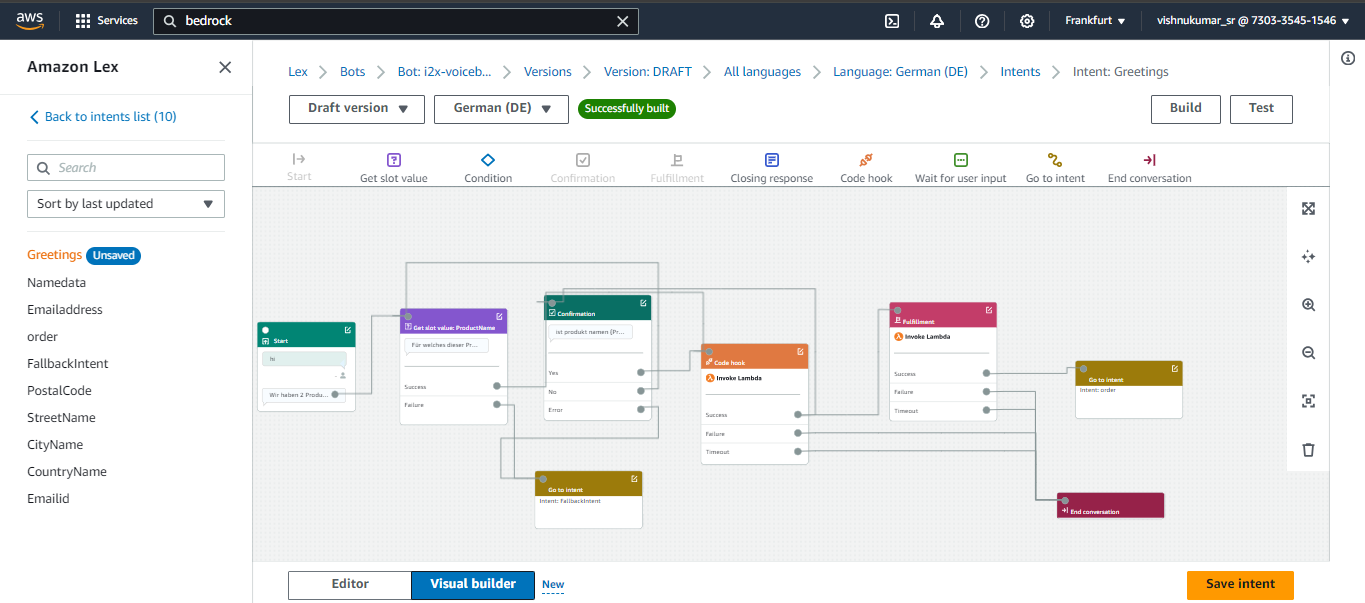
You can click the Visual Builder option to view your flow in Lex V2 bot let’s discuss what each block does and we can simply drag and drop these blocks to create the flow . Lambda Block or code hook block are used in the flow when you want your bot to retrieve information from different services(S3 which is done in a lambda function). For example my product details like price, size, weight all are stored in a S3 bucket to retrieve the data and we are also using fuzzy logic to match the closest response. we can invoke only one lambda function per bot so we have added the logic passing the customer input to the Mistral 8X7 model for verification and for storing the final output with the audio folder to the DynamoDB.
Lambda Function
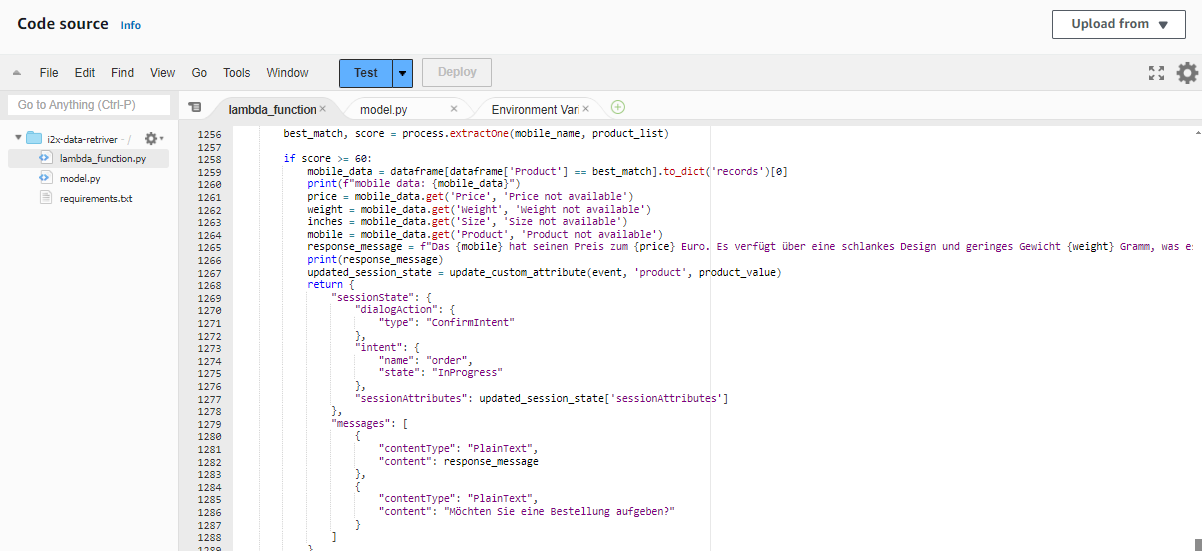
This Lambda Function is used to retrieve the product information after getting the customers input. For example when the customer says Apple iPhone the lambda function brings the details from the S3 bucket and it matches it using the fuzzy logic we have set the score to a threshold of 80 or more if the score of user input matches the threshold value it will return the product details and move to the next intent. The bots expects a response with in 3-4 seconds after it asking the user intent if no response is received (when the caller is on silent or hasn’t said anything) the bot was initially taking the empty string as response and it directly connected to the agent but we have included a logic to continue the flow by asking for the input again if it receives an empty input.In the next session let's look how to store the data in aDynamoDB table do look at the references below.
Sample Calls
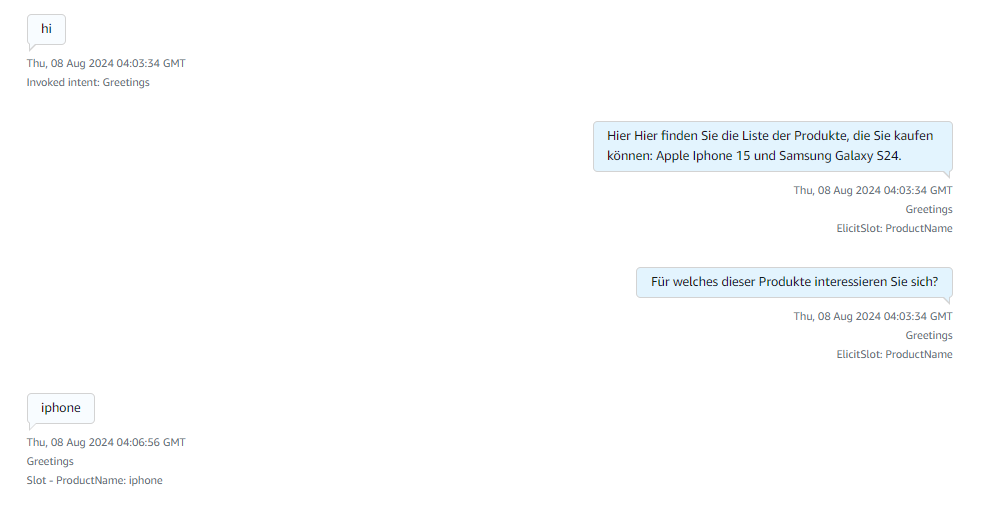
Here after receiving the greeting the available products information is responded and ask for what product they are looking for.
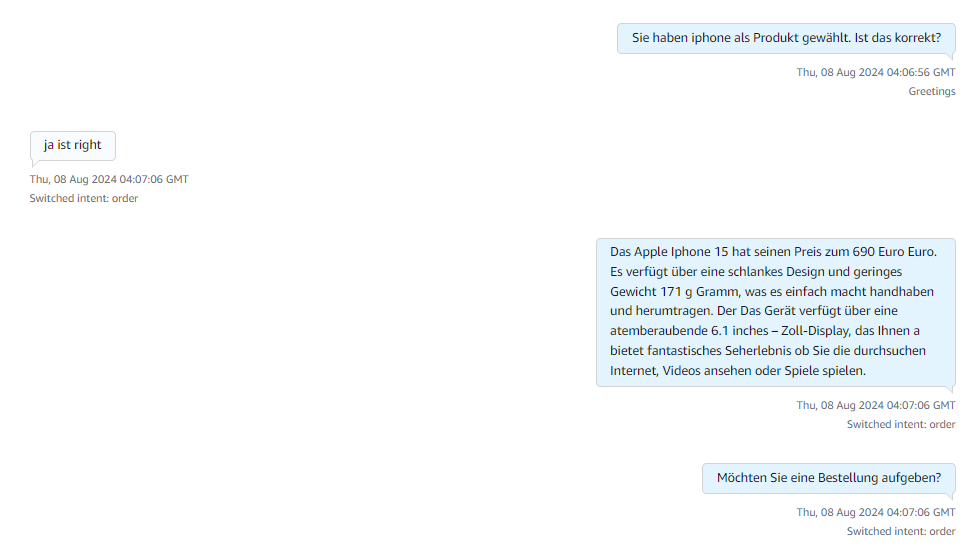
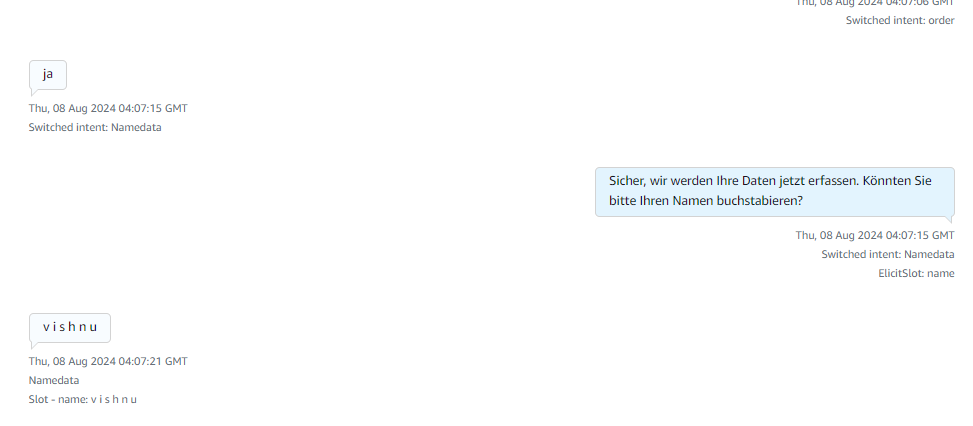
After receiving the product name it explains about the products and asks for order confirmation if yes it starts collecting caller details if no or if there are no products matching the caller requirement then it connects to the human agent for more information.
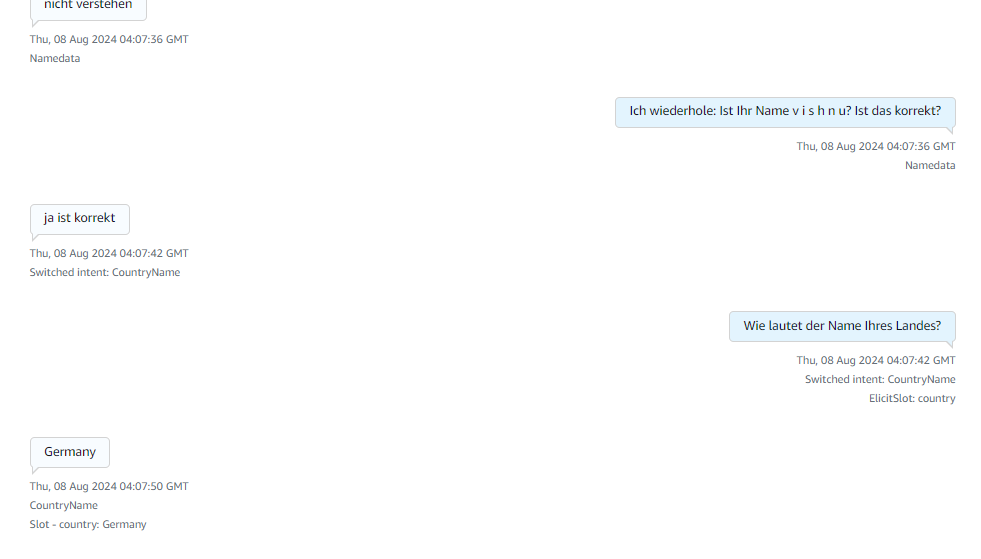
Here in the above image it collects details like name and the country details of the caller.
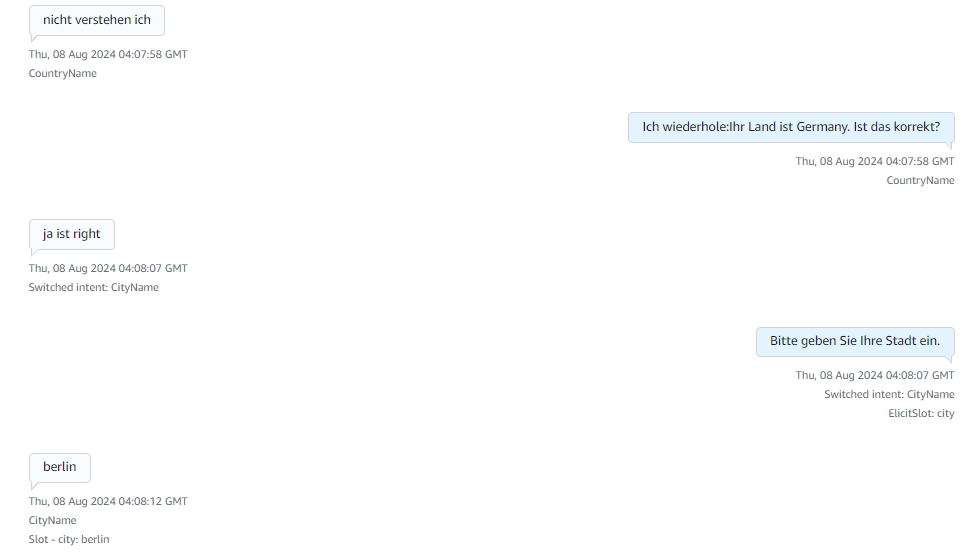
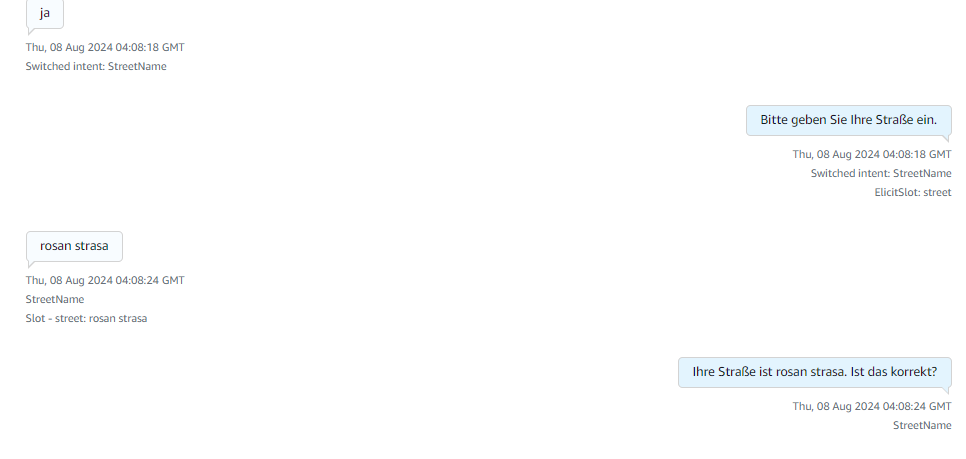
Then it starts collecting the city name and the street name of the caller.
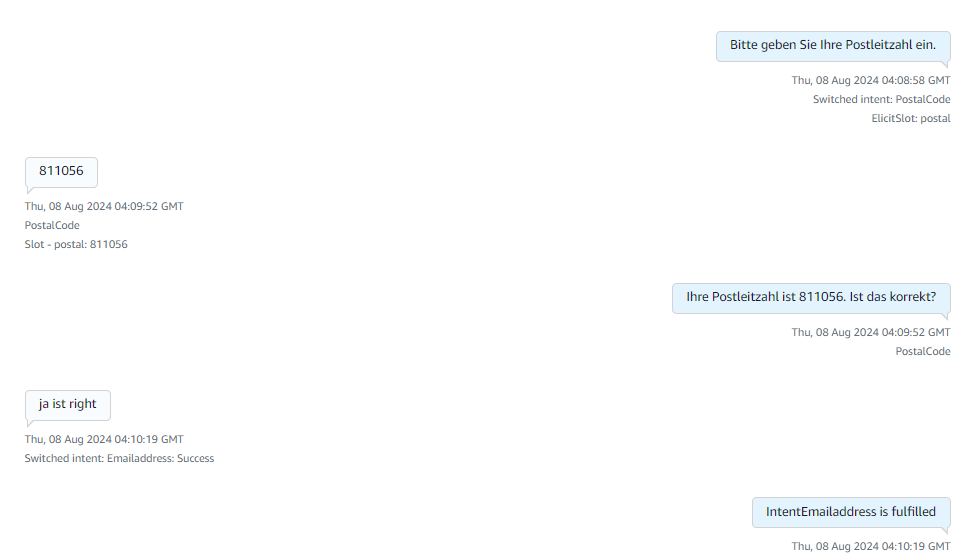
Finally it collects the zip code/postal code and replies to a thankyou message with an order confirmation message from the lex. These images describe the complete flow of how Amazon Lex responds to the customer. It has incorporated a retry logic of max 3 times where the bot asks the customer if it is not able to understand the customer intent. The bot has been trained to connect to a human agent if it is not able to respond or if the customer directly says that they wanted to talk to an agent. After reaching the Email Address intent Fallback it will give a thankyou message and will connect to the agent if the customer has any doubts.
References
Region requirements for ordering and porting phone numbers - Amazon Connect
2
.png)
Supercharge Your AI Systems with Gemini 1.5: Advanced Features & Techniques
In the ever-competitive race to build faster, smarter, and more aware LLMs, every new month has a major announcement of a new family of models. And since the Gemini 1.5 family, consisting of Nano, Flash, Pro, and Ultra have been out since May 2024, many developers have already had their chance to work with them. And any of those developers can tell you one thing: Gemini 1.5 isn’t just a step ahead. It’s a great big leap forward.
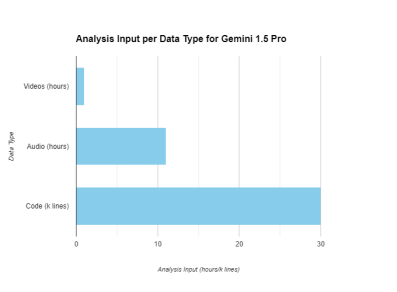
Gemini is an extremely versatile and functional model, it comes equipped with a 2 million input context window. This means that prompts can be massive. And one may think that this will cause performance issues in the model’s outputs, but Gemini consistently delivers accurate, compliant, and context-aware responses, no matter how long the prompt is. And the lengths of the prompts mean that users can push large data files along with the prompt. The 2 million token input window equates to 1 hour of videos, 11 hours of audio, and 30k lines of code to be analyzed at once through Gemini 1.5 pro.
With all that being said, deciding which approach to take towards building a conversational system using Gemini 1.5 varies greatly depending on what the developer is trying to achieve.
All the methods require a general set-up procedure:
1. Google Cloud Project: A GCP project with the Vertex AI API enabled to access the Gemini model.
2. Python Environment: A Python environment with the necessary libraries (vertexai, google-cloud-aiplatform) installed.
3. Authentication: Proper authentication setup, which includes creating a service account with access to the VertexAI platform: roles such as VertexAI User. Then, a key needs to be downloaded to the application environment. This service account needs to be set as the default application credentials in the environment:
Python
import os
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "path/to/service/account/key"
4. Model Selection: Choosing the appropriate Gemini model variant (Nano, Flash, Pro, Ultra) based on your specific needs.
Gemini models can be accessed through the Python SDK, VertexAI, or through LLM frameworks such as Langchain. However, for this piece, we will stick to using the Python SDK, which can be installed using:
Unset
pip install vertexai
pip install google-cloud-aiplatform
To access Gemini through this method, the VertexAI API must be enabled on a google cloud project. The details of this project need to be instantiated, so that Gemini can be accessed through the client SDK.
Python
vertexai.init(project="project_id", location="project_location")
From here, to access the model and begin prompting, an instance of the model needs to be imported from the GenerativeModel module in vertexai. This can be done by:
Python
from vertexai.generative_models import GenerativeModel, ChatSession, Part model_object = GenerativeModel(model_name="gemini-1.5-flash-001", system_instruction="You are a helpful assistant who
reads documents and answers questions.")
From here, we are ready to start prompting our conversational system. But, as Gemini is so versatile, there are many methods to interact with the model, depending on the use case. In this piece, I will cover the three main methods, and the ones I see as the most practical for building architectures:
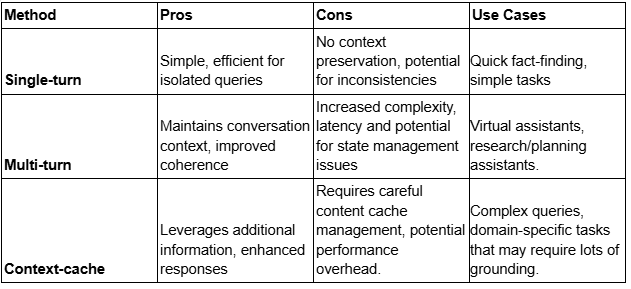
Chat Session Interaction
VertexAI generative models are able to store their own history while the instance is open. This means that no external service is needed to store the conversation history. This history can be saved, exported, and further modified. Now, the history object comes as an attribute to the ChatSession object that we imported earlier. This ChatSession object can be instantiated by:
Python
chat = ChatSession(model=model_object)
Further attributes can be added, including the aforementioned chat history which allows the model to have a simulated history to continue the conversation from. This chat session object is the interface between the user and the model. When a new prompt needs to be pushed to the ChatSession, that can be accomplished by using:
Python
chat.send_message(prompt, stream=False )
This method simulates a multi-turn chat session, where context is preserved throughout the whole conversation, until the instance of the chat session is active. The history is maintained by the chat session object, which allows the user to ask more antecedent driven questions, such as “What did you mean by that?”, “How can I improve this?”, where the object isn’t clear. This chat session method is ideal for chat interface scenarios, such as chatbots, personal assistants and more.
The history created by the model can be saved later and reloaded, during the instantiation of the chat session model, like so:
Python
messages = chat.history
chat = ChatSession(model=model, history=history)
And from here, the chat session can be continued in the multiturn chat format. This method is very straightforward and eliminates the need to have external frameworks such as Langchain to manage conversations, and load them back into the model. This method maintains the full functionality of the Gemini models while minimizing the overhead required to have a full chat interface.
Single Turn Chat Method
If the functionality required doesn’t call for a multi turn chat methodology, or there isn’t a need for history to be saved, the Gemini SDK includes methods that work as a single turn chat method, similar to how image generation interfaces work. Each
call to the model acts as an independent session with no session tracking, or knowledge of past conversations. This reduces the overhead required to create the interface while still having a fully functional solution.
For this method, the model object can be used directly, like so:
Python
model = genai.GenerativeModel("gemini-1.5-flash")
response = model.generate_content("What is the capital of Karnataka?") print(response.text)
Here, a message is pushed to the model directly without any history or context added to the prompt. This method is beneficial for any use case that only requires a single turn messaging, for example grammar correction, some basic suggestions, and more.
Context Caching
Typically, LLMs aren’t used on their own, they are grounded with a source of truth. This allows them to have a knowledge bank when they answer questions, which reduces the chances that they hallucinate, or get information wrong. This is accomplished by using a RAG system. However, Gemini 1.5 makes that process unnecessary. Of course, one could just push the extracted text of a document completely into the prompt, but if a cache of documents is too large –33,000 tokens or larger– VertexAI has a method for that: Context Caching.
Context caching works by pushing a whole load of documents along with the model into a variable, and initiating a Chat Session from this cache. This eliminates the need to create a rag pipeline, as the model has the documentation to refer to on demand.
Python
contents = [
Part.from_uri(
"gs://cloud-samples-data/generative-ai/pdf/2312.11805v3.pdf",
mime_type="application/pdf",
),
Part.from_uri(
"gs://cloud-samples-data/generative-ai/pdf/2403.05530.pdf",
mime_type="application/pdf",
),
]
cached_content = caching.CachedContent.create(
model_name="gemini-1.5-pro-001",
system_instruction=system_instruction,
contents=contents,
ttl=datetime.timedelta(minutes=60),
)
The cached documents can be sourced from any GCP storage location, and are formatted into a Part object. These Part objects are essentially a data type that make up the multi turn chat formats. These objects are collated along with the prompt into a list and pushed to the Cache object. Along with the contents, a time to live parameter is also expected. This gives an expiration time for the cache, which aids in security and memory management.
Now, to use this cache, a model needs to be created from the cache variable. This can be done through:
Python
model = GenerativeModel.from_cached_content(cached_content=cached_content) response = model.generate_content("What are the papers about?")
#alternatively, a ChatSession object can be used with this model to create a multiturn chat interface.
The key advantage of the Gemini 1.5 family of models is that they have unparalleled support for multimodal prompts. The Part objects can be used to encode all types of inputs. By adjusting the mime-type parameter, the part object can represent any type of input, including audio, video, and images. Whatever the input type, the object can be appended to the input list, and the model will interpret it exactly as you need it to.
And voila! You’ve made your very own multimodal AI assistant using Gemini 1.5. Note that this is just a jumping off point. The VertexAI SDK has functionality that supports building complex Agentic systems, image generation, model tuning and more. The scope of Google’s foundational models and the surrounding support structure is ever-growing, and gives seasoned developers and newbies alike unprecedented power to build groundbreaking, superbly effective, and responsible applications.
2

Deploying Your Project on Google Cloud: From Manual Setup to Automated CD Pipeline with Secure Git Integration
Imagine you've just put the finishing touches on your latest application. Now comes the challenging part: deploying it on Google Cloud's Compute Engine instances. The initial setup is like assembling a complex jigsaw puzzle: creating a Managed Instance Group (MIG) with auto-scaling and auto-healing, pushing your dockerized application to Artifact Registry, configuring URL maps, forwarding rules, backends, and finally, a load balancer to distribute traffic.
In the current landscape of software development, while automating code improvement remains a challenge, optimizing infrastructure management for code updates is achievable. With the involvement of iterative development methodologies, it's crucial to minimize the time and effort required for code deployment.
This blog introduces and executes an efficient Continuous Deployment (CD) pipeline leveraging Git triggers on Cloud Build within Google Cloud Platform (GCP). My approach integrates SSH key authentication, enhancing both security and automation. We'll explore how to set up a Git trigger that activates whenever changes are pushed to your repository. We'll dive into configuring Cloud Build to work with these triggers, incorporating crucial security elements like Secret Manager for handling sensitive credentials, setting up GitHub SSH keys for secure, and also setting up SSH keys to maintain secure access of your deployment on your GCP infrastructure and thus lead to seamless integration.
These steps eliminate the need for repetitive infrastructure setup with each code iteration, significantly reducing deployment overhead and enabling rapid, secure updates to your production environment.
Before jumping into the implementation, let's understand the concept of Continuous Deployment (CD) in the context of Git-based version control. CD is a DevOps practice where code changes are automatically built, tested, and deployed to production environments automatically. In the Google Cloud Platform (GCP) ecosystem, Cloud Build serves as a robust CI/CD tool that can ingest source code from diverse Version Control Systems (VCS) or cloud storage solutions, execute builds according to user-defined specifications, and generate deployment artifacts such as Docker images or Java ARchives (JARs).
Let's dive into setting up the whole CD pipeline now;
To implement GitHub triggers effectively, the initial step involves properly structuring and updating your repository with the latest codebase. It's absolutely necessary that the person configuring the Cloud Build trigger possesses the requisite permissions on the target repository. Specifically, they should have collaborator status or equivalent access rights to enable seamless integration between GitHub events and the deployment pipeline. This ensures that the CD system can respond to repository updates and initiate the deployment process.
Before proceeding with the setup, ensure that the Cloud Build API and the Secret Manager API are enabled in your Google Cloud environment. These can be activated via the Google Cloud Console's API Marketplace.
Establishing GitHub SSH keys for secure repository connection
For this, open up your cloud shell on your console and wait for it to connect. Now type in the following commands:
mkdir workingdir && cd workingdir
To generate your github key run this line replace the github-email with the email id that you have used to create your repository on Github
ssh-keygen -t rsa -b 4096 -N '' -f id_github -C github-email
This generates a 4096-bit RSA key pair without a passphrase, which is crucial, as Cloud Build doesn't support passphrase-protected keys.
Secure Private Key Storage on Secret Manager
Now after the above steps you would have a private and a public Github key. The private key (id_github) must be securely stored in Secret Manager to prevent unauthorized access. To do so follow these steps:
a. Navigate to the Secret Manager in Google Cloud Console.
b. Select 'Create Secret'.
c. Assign a descriptive name to the secret.
d. For the secret value, upload the 'id_github' file from your workingdir.
e. Maintain default region settings unless specific requirements dictate otherwise.
f. Finalize by clicking 'Create secret'
Once these steps are done you can be assured that your private key is protected and isn’t accessible to everyone.
Connecting to your Github repository
Now that you have your Git keys it is necessary to add the public key on GitHub so as to connect it to your infrastructure on GCP. So log into your GitHub account move into your repository page and follow these steps:
a. Move to the Settings tab of your repository
c. In the sidebar, select 'Deploy Keys' and click 'Add deploy key'.
d. Provide a descriptive title and paste the contents of 'workingdir/id_github.pub'. This is your public key
e. Enable 'Allow write access'.
f. Confirm by clicking 'Add key'.
Once you have added the Git keys to the Secret manager and your GitHub repository Access key section you can continue and remove the local copies. This adds another level of security and makes sure nobody else is able to access your GitHub key. To do so run this on your cloud shell:
rm id_github*
Configuring Cloud Build Service Account Permissions
Now that you have the above set you need to make sure that the Service Account that you are using has access to the Secret Manager.
a. Navigate to the Cloud Build Settings page in Google Cloud Console.
b. Select the service account for your build operations.
c. Enable the 'Secret Manager Secret Assessor' role for this account.
Preparing Known Hosts for GitHub
The 'known_hosts' file is a critical component of SSH security, playing a vital role in preventing man-in-the-middle (MITM) attacks. Therefore, the final step is to set up your known hosts file.
We save the GitHub public key for SSH verification in the known_hosts file. Go ahead use this command and create a known_hosts file in the working directory
ssh-keyscan -t rsa github.com > known_hosts.github
Make sure to download the 'known_hosts.github' file to the appropriate location in the build environment, in this case your Github repository.
With the GitHub SSH keys properly configured and securely stored, the next critical step is to create your cloudbuild.yaml configuration file. This YAML file defines the series of steps Cloud Build will execute during the deployment process.
For deploying applications to Compute Engine instances via SSH, it's imperative to set up authentication keys with the appropriate access permissions. These keys will enable Cloud Build to securely push code and execute commands on your Compute Engine Managed Instance Groups (MIGs).
In the next section, we'll delve into the details of setting up these SSH keys for Compute Engine. This final piece will complete our Continuous Deployment (CD) pipeline, enabling automated deployments to Compute Engine MIGs via SSH.
Configuring SSH keys for secure access to Compute Engine instances
This step is crucial for ensuring that our Cloud Build processes can securely interact with our deployment targets. Let's walk through this process, addressing common pitfalls and best practices along the way.
1. Generating SSH Keys
Create a folder named ssh_keys on your Cloud Editor. Inside that, create a blank text file called id_rsa.txt. This is where your SSH keys will be stored: both public and private.
Let's start by generating the SSH keys. Replace the italics values in the command below and run it on your cloud shell.
ssh-keygen -t rsa -f ~/enter_path_to_id_rsa.txt -C your_username -b 2048
The addition of 2048 generates a 2048-bit RSA key pair, which offers a good balance of security and performance.
2. Enter into your instance through the shell through the following command. Now the changes and the directories of files you make will all be saved in your instance memory. Make sure that you have allotted enough memory during instance formation or MIG template formation.
gcloud compute ssh username@instance_name --zone instance_zone
3. Adding SSH Keys to Compute Engine Metadata
Once you have your key pair, you need to add the public key to your Compute Engine instance's metadata. This allows you to access the SSH on that particular instance.This can be done using the following gcloud command paste this on the:
gcloud compute instances add-metadata instance_name \
--metadata ssh-keys="username:$(location_of_public_key/id_rsa.pub)" \
--zone instance_zone \
--project project_id
Replace the name of the instance with your compute engine instance name, followed by your username, location of public key, zone in which the instance is created and finally your project id.
4. Configuring the Instance for SSH Access
Now that you have added the public key to your instance metadata, in order to access the instance you would need to add the private key in the authorized_keys file in the instance ssh folder. This private key is verified with your public key from the metadata to give access to the ssh and further processing.
On your Compute Engine instance paste the following commands to set up the authorized_keys file:
mkdir -p ~/.ssh
nano ~/.ssh/authorized_keys
The nano command opens an editor. Paste your key in this file and then save it accordingly.
Next, let's set up the correct permissions for the keys, paste these commands in the shell:
chmod 700 ~/.ssh
chmod 600 ~/.ssh/authorized_keys
These permissions are crucial for security - SSH will refuse to work if the permissions are too open.
5. Testing Your SSH Connection
Once you have executed all the above steps your SSH connection should be set. You can test your SSH connection using the verbose flag to diagnose any issues:
ssh -v -i ~/ssh_keys/id_rsa username@external_ip_of_instance
These steps lead to the completion of your CD setup and you can seamlessly integrate your code on github to your production environment.
Before you are fully ready make sure that you have docker properly installed and running in your instance. An error commonly faced while handling docker are docker authentication issues.
COMMON ISSUE
If you encounter errors like 'Unauthenticated request' when pulling Docker images, you may need to add the appropriate IAM roles. Run this command to do so:
gcloud projects add-iam-policy-binding project_id \
--member=serviceAccount:service_account_name\
--role=roles/artifactregistry.reader
Also, configure Docker to authenticate with GCR:
gcloud auth configure-docker gcr.io --quiet
With these steps you are ready with your deployment pipeline along with continuous deployment pipeline and can seamlessly integrate updates directly from your github to production environment on the Google Cloud Platform.
There might be cases where the production code that you just deployed even after multiple checks might fail and you would want to return to the previous version. This can be taken care of by the rollback method in which you can return to the previous version on your deployed code. To do this you do have an option through the console where you can choose roll back. But if you do want to continue on shell and run it though there follow this command and replace it with the correct variables.
gcloud deploy targets rollback TARGET_NAME \ --delivery-pipeline= PIPELINE_NAME \ --release= RELEASE_NAME \ --rollout-id= ROLLOUT_ID
With this do make sure that deploying bugged code on production can lead to serious downtime on your application as well as loss of data so make sure that your code is fully tested and runs smoothly with traffic before pushing it to production.
Conclusion
The art of deploying applications on Google Cloud with a secure and automated CD pipeline is more than just a technical achievement—it's a step towards streamlined, efficient development. By meticulously configuring SSH keys and leveraging Git triggers, you ensure not only the integrity of your deployment process but also the speed and reliability of your updates. This approach eliminates manual errors, reduces operational overhead, and accelerates the delivery of new features to production.
As you continue refining your cloud infrastructure, the lessons from setting up this pipeline—such as securing credentials with Secret Manager and optimizing your GitHub integration—will serve as a strong foundation. With this setup, you're not just keeping up with the fast-paced world of DevOps; you're leading the charge towards a more secure, automated future.
2
Building an Automated Voice Bot with Amazon Connect, Lex V2, and Lambda for Real-Time Customer Interaction
Today we are going to build a completely automated Voice Bot or to set up a call center flow which can provide you with real time conversation by using Amazon connect, Lex V2, DynamoDB, S3 and Lambda Function services available in the amazon console. The voice bot is built in German and below is the entire flow that is followed in this blog.
Advantages of using Lex bot
- Lex enables any developer to build conversational chatbots quickly.
- No deep learning expertise is necessary—to create a bot, you just specify the basic conversation flow in the Amazon Lex console. The ASR (Automatic Speech Recognition) part is internally taken care of lex so we don’t have to worry about that. You seamlessly integrate lambda functions, DynamoDB, Cognito and other services of AWS.
- Compared to other services Amazon Lex is cost effective.
Architecture Diagram
Architecture
Within the AWS environment, Amazon Connect is a useful tool for establishing a call center. It facilitates customer conversations and creates a smooth flow that combines with a German-trained Lex v2 bot. This bot is made to manage a range of client interactions, gathering vital data via slots (certain data points the bot needs) and intents (activities the bot might execute). The lex bot is then attached to a lambda function which gets triggered when the customer responds with a product name if not it directly connects the customer to the human agent for further queries.
The lambda function first finds the product name from the customer input then it is compared with the product's list which we have in the S3 bucket where it has details like price, weight, size, etc.. from an excel sheet (excel sheet) that now contains only two products namely Samsung Galaxy S24 and Apple iPhone 15 with the pricing weight and size of the product. The customer's input is matched with the closest product name in the excel sheet using the fuzzy matching algorithm.
The threshold for this matching of products is set to 60 or more which can be altered based on the need. Only if the customer wants to order, the bot starts collecting customer details like name and other details. The bot has a confirmation block which responds to the customer with what it understood from the customer input(like an evaluation ) if the customer doesn’t confirm it asks for that particular intent again. If you need, we can add the retry logic. Here a max retry of 3 is set to all the customer details just to make sure the bot retrieves the right data from the customers while transcribing from speech to text (ASR).
After retrieving the data from the customer before storing them we can verify the data collected from the customer is valid or not by passing it to the Mixtral 8x7B Instruct v0.1 model here i am using this model because my conversation will be in German and since the mistral model is trained in German and other languages it will be easy for me to process this model is called using the Amazon Bedrock service. We are invoking this model in the lambda function which has a prompt template which describes a set of instructions for example here i am giving instructions like just extract the product name from the callers input. After getting the response from LLM the output is then stored as session attributes in code snippet below along with the original data and the call recordings segments from the s3 bucket.
def update_custom_attribute(event, field_name, field_value):
session_state = event['sessionState']
if 'sessionAttributes' not in session_state:
session_state['sessionAttributes'] = {}
if 'userInfo' not in session_state['sessionAttributes']:
user_info = {}
else:
user_info = json.loads(session_state['sessionAttributes']['userInfo'])
updated_session_state = update_custom_attribute(event, 'name', name_value)
return {
"sessionState": {
"dialogAction": {
"type": "ElicitSlot",
"slotToElicit": "country"
},
"intent": {
"name": "CountryName",
"state": "InProgress",
"slots": {}
},
"sessionAttributes": updated_session_state['sessionAttributes']
},
"messages": [
{
"contentType": "PlainText",
"content": "what is the name of your country?"
}
]
}
Finally the recordings are stored in the dynamo db. with the time as primary key so that each record is unique.
AMAZON CONNECT
This is how the interface of Amazon Connect looks like you can create a new instance by clicking the add an instance button. you can specify the name of the URL connect instance. After creating the instance click the emergency login/access URL(sign in with the user account you created while creating the instance).
The below image creates the toll free numbers where you select the phone icon and select the phone number and click claim a number then select the voice for voice bot and the country in which you want to create the number for and click the save button remember while you are claiming the number for few countries you need to submit proof of documents refer this document [1] .
Next, create the working hours from the flow arrow of the console. I have created a 9 A.M to 5 P.M so that i can connect the call to the human agent if the caller has any queries. But if you want your voice bot to be available 24/7 then change the availability or create a new hours of operations.
Next create a queue and add the hours of operation in the queue. That's it we are almost done setting up a few things in the Amazon Connect now lets go inside the flows and look how our complete flow looks like.
This above diagram is the Amazon Connect Flow where the set voice block is used to set a specific voice. The set logging behavior block and set recording and analytics behavior is used to record the conversation after connecting to the agent. Play prompt is used to respond a simple prompt saying the call is recorded. The set contacts attribute block contains two session attributes one for focusing on the user’s voice rather than the background noise and another is to not barge in when the bot is responding after adding these two session attributes in the connect flow the call is able to pass the flow even when there a certain amount of background noise. The get customer input block is used for connecting the call to the lex bot if the customer wants to connect to the agent the set working queue ensures to connect to the agent. Finally the call is disconnected using the disconnect block.
AMAZON LEX
Next, We can create a bot from scratch by clicking on the create bot icon on the lex console. you can specify the name of the bot with the required IAM permissions and select “no” for the child protection. In the next step choose the language you want your bot to train and select the voice. The intent classification score is set in between 0 to 1. It is similar to a threshold where the bot can classify the customers/user reason for example, if i have multiple intent based on the score it connects to the most likely intent. you can also add multiple languages to train your
bot.
You can create an intent to know the customers/callers need for calling like, Ordering a mobile in our case we expect a product name from the customer like Samsung galaxy or apple iPhone. The sample utterances are used to initiate the conversation with the bot at the very beginning of the conversation for example we can say hi, hello, i want to order, etc. to trigger the intent that you expect your bot to responded based the customer reason. If you have multiple intents like greetings, order, address you connect these intent in a flow one after other in a flow using the go to intent block.
Slots are used to fulfill the intent like for example here the bot needs to know which product the customer wants to order to complete this greetings intent. Likewise you can create slots in a single intents or create separate slots in each intent and connect them in the flow. The confirmation block is used for rechecking the user input like the product name based on the response from the customer (if the customer says “yes” it will go to the next step if “no” then it goes to the previous state and asks the question again).
You can improve the accuracy of the lex bot by recognizing what the customer is saying speech recognition (ASR) by creating a custom slot type and training the bot with a few examples of what the customer might say. For example, in our case the customer might say the product names like iPhone, apple iPhone, iPhone 15 etc.. so add few values in the slot utterances which can improve the speech detection. You can create multiple custom slot types like product name, customer name, address, etc..
You can click the Visual Builder option to view your flow in Lex V2 bot let’s discuss what each block does and we can simply drag and drop these blocks to create the flow . Lambda Block or code hook block are used in the flow when you want your bot to retrieve information from different services(S3 which is done in a lambda function). For example my product details like price, size, weight all are stored in a S3 bucket to retrieve the data and we are also using fuzzy logic to match the closest response. we can invoke only one lambda function per bot so we have added the logic passing the customer input to the Mistral 8X7 model for verification and for storing the final output with the audio folder to the DynamoDB.
Lambda Function
This Lambda Function is used to retrieve the product information after getting the customers input. For example when the customer says Apple iPhone the lambda function brings the details from the S3 bucket and it matches it using the fuzzy logic we have set the score to a threshold of 80 or more if the score of user input matches the threshold value it will return the product details and move to the next intent. The bots expects a response with in 3-4 seconds after it asking the user intent if no response is received (when the caller is on silent or hasn’t said anything) the bot was initially taking the empty string as response and it directly connected to the agent but we have included a logic to continue the flow by asking for the input again if it receives an empty input.In the next session let's look how to store the data in aDynamoDB table do look at the references below.
Sample Calls
Here after receiving the greeting the available products information is responded and ask for what product they are looking for.
After receiving the product name it explains about the products and asks for order confirmation if yes it starts collecting caller details if no or if there are no products matching the caller requirement then it connects to the human agent for more information.
Here in the above image it collects details like name and the country details of the caller.
Then it starts collecting the city name and the street name of the caller.
Finally it collects the zip code/postal code and replies to a thankyou message with an order confirmation message from the lex. These images describe the complete flow of how Amazon Lex responds to the customer. It has incorporated a retry logic of max 3 times where the bot asks the customer if it is not able to understand the customer intent. The bot has been trained to connect to a human agent if it is not able to respond or if the customer directly says that they wanted to talk to an agent. After reaching the Email Address intent Fallback it will give a thankyou message and will connect to the agent if the customer has any doubts.
References
Region requirements for ordering and porting phone numbers - Amazon Connect
Supercharge Your AI Systems with Gemini 1.5: Advanced Features & Techniques
In the ever-competitive race to build faster, smarter, and more aware LLMs, every new month has a major announcement of a new family of models. And since the Gemini 1.5 family, consisting of Nano, Flash, Pro, and Ultra have been out since May 2024, many developers have already had their chance to work with them. And any of those developers can tell you one thing: Gemini 1.5 isn’t just a step ahead. It’s a great big leap forward.
Gemini is an extremely versatile and functional model, it comes equipped with a 2 million input context window. This means that prompts can be massive. And one may think that this will cause performance issues in the model’s outputs, but Gemini consistently delivers accurate, compliant, and context-aware responses, no matter how long the prompt is. And the lengths of the prompts mean that users can push large data files along with the prompt. The 2 million token input window equates to 1 hour of videos, 11 hours of audio, and 30k lines of code to be analyzed at once through Gemini 1.5 pro.
With all that being said, deciding which approach to take towards building a conversational system using Gemini 1.5 varies greatly depending on what the developer is trying to achieve.
All the methods require a general set-up procedure:
1. Google Cloud Project: A GCP project with the Vertex AI API enabled to access the Gemini model.
2. Python Environment: A Python environment with the necessary libraries (vertexai, google-cloud-aiplatform) installed.
3. Authentication: Proper authentication setup, which includes creating a service account with access to the VertexAI platform: roles such as VertexAI User. Then, a key needs to be downloaded to the application environment. This service account needs to be set as the default application credentials in the environment:
Python
import os
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "path/to/service/account/key"
4. Model Selection: Choosing the appropriate Gemini model variant (Nano, Flash, Pro, Ultra) based on your specific needs.
Gemini models can be accessed through the Python SDK, VertexAI, or through LLM frameworks such as Langchain. However, for this piece, we will stick to using the Python SDK, which can be installed using:
Unset
pip install vertexai
pip install google-cloud-aiplatform
To access Gemini through this method, the VertexAI API must be enabled on a google cloud project. The details of this project need to be instantiated, so that Gemini can be accessed through the client SDK.
Python
vertexai.init(project="project_id", location="project_location")
From here, to access the model and begin prompting, an instance of the model needs to be imported from the GenerativeModel module in vertexai. This can be done by:
Python
from vertexai.generative_models import GenerativeModel, ChatSession, Part model_object = GenerativeModel(model_name="gemini-1.5-flash-001", system_instruction="You are a helpful assistant who
reads documents and answers questions.")
From here, we are ready to start prompting our conversational system. But, as Gemini is so versatile, there are many methods to interact with the model, depending on the use case. In this piece, I will cover the three main methods, and the ones I see as the most practical for building architectures:
Chat Session Interaction
VertexAI generative models are able to store their own history while the instance is open. This means that no external service is needed to store the conversation history. This history can be saved, exported, and further modified. Now, the history object comes as an attribute to the ChatSession object that we imported earlier. This ChatSession object can be instantiated by:
Python
chat = ChatSession(model=model_object)
Further attributes can be added, including the aforementioned chat history which allows the model to have a simulated history to continue the conversation from. This chat session object is the interface between the user and the model. When a new prompt needs to be pushed to the ChatSession, that can be accomplished by using:
Python
chat.send_message(prompt, stream=False )
This method simulates a multi-turn chat session, where context is preserved throughout the whole conversation, until the instance of the chat session is active. The history is maintained by the chat session object, which allows the user to ask more antecedent driven questions, such as “What did you mean by that?”, “How can I improve this?”, where the object isn’t clear. This chat session method is ideal for chat interface scenarios, such as chatbots, personal assistants and more.
The history created by the model can be saved later and reloaded, during the instantiation of the chat session model, like so:
Python
messages = chat.history
chat = ChatSession(model=model, history=history)
And from here, the chat session can be continued in the multiturn chat format. This method is very straightforward and eliminates the need to have external frameworks such as Langchain to manage conversations, and load them back into the model. This method maintains the full functionality of the Gemini models while minimizing the overhead required to have a full chat interface.
Single Turn Chat Method
If the functionality required doesn’t call for a multi turn chat methodology, or there isn’t a need for history to be saved, the Gemini SDK includes methods that work as a single turn chat method, similar to how image generation interfaces work. Each
call to the model acts as an independent session with no session tracking, or knowledge of past conversations. This reduces the overhead required to create the interface while still having a fully functional solution.
For this method, the model object can be used directly, like so:
Python
model = genai.GenerativeModel("gemini-1.5-flash")
response = model.generate_content("What is the capital of Karnataka?") print(response.text)
Here, a message is pushed to the model directly without any history or context added to the prompt. This method is beneficial for any use case that only requires a single turn messaging, for example grammar correction, some basic suggestions, and more.
Context Caching
Typically, LLMs aren’t used on their own, they are grounded with a source of truth. This allows them to have a knowledge bank when they answer questions, which reduces the chances that they hallucinate, or get information wrong. This is accomplished by using a RAG system. However, Gemini 1.5 makes that process unnecessary. Of course, one could just push the extracted text of a document completely into the prompt, but if a cache of documents is too large –33,000 tokens or larger– VertexAI has a method for that: Context Caching.
Context caching works by pushing a whole load of documents along with the model into a variable, and initiating a Chat Session from this cache. This eliminates the need to create a rag pipeline, as the model has the documentation to refer to on demand.
Python
contents = [
Part.from_uri(
"gs://cloud-samples-data/generative-ai/pdf/2312.11805v3.pdf",
mime_type="application/pdf",
),
Part.from_uri(
"gs://cloud-samples-data/generative-ai/pdf/2403.05530.pdf",
mime_type="application/pdf",
),
]
cached_content = caching.CachedContent.create(
model_name="gemini-1.5-pro-001",
system_instruction=system_instruction,
contents=contents,
ttl=datetime.timedelta(minutes=60),
)
The cached documents can be sourced from any GCP storage location, and are formatted into a Part object. These Part objects are essentially a data type that make up the multi turn chat formats. These objects are collated along with the prompt into a list and pushed to the Cache object. Along with the contents, a time to live parameter is also expected. This gives an expiration time for the cache, which aids in security and memory management.
Now, to use this cache, a model needs to be created from the cache variable. This can be done through:
Python
model = GenerativeModel.from_cached_content(cached_content=cached_content) response = model.generate_content("What are the papers about?")
#alternatively, a ChatSession object can be used with this model to create a multiturn chat interface.
The key advantage of the Gemini 1.5 family of models is that they have unparalleled support for multimodal prompts. The Part objects can be used to encode all types of inputs. By adjusting the mime-type parameter, the part object can represent any type of input, including audio, video, and images. Whatever the input type, the object can be appended to the input list, and the model will interpret it exactly as you need it to.
And voila! You’ve made your very own multimodal AI assistant using Gemini 1.5. Note that this is just a jumping off point. The VertexAI SDK has functionality that supports building complex Agentic systems, image generation, model tuning and more. The scope of Google’s foundational models and the surrounding support structure is ever-growing, and gives seasoned developers and newbies alike unprecedented power to build groundbreaking, superbly effective, and responsible applications.
Deploying Your Project on Google Cloud: From Manual Setup to Automated CD Pipeline with Secure Git Integration
Imagine you've just put the finishing touches on your latest application. Now comes the challenging part: deploying it on Google Cloud's Compute Engine instances. The initial setup is like assembling a complex jigsaw puzzle: creating a Managed Instance Group (MIG) with auto-scaling and auto-healing, pushing your dockerized application to Artifact Registry, configuring URL maps, forwarding rules, backends, and finally, a load balancer to distribute traffic.
In the current landscape of software development, while automating code improvement remains a challenge, optimizing infrastructure management for code updates is achievable. With the involvement of iterative development methodologies, it's crucial to minimize the time and effort required for code deployment.
This blog introduces and executes an efficient Continuous Deployment (CD) pipeline leveraging Git triggers on Cloud Build within Google Cloud Platform (GCP). My approach integrates SSH key authentication, enhancing both security and automation. We'll explore how to set up a Git trigger that activates whenever changes are pushed to your repository. We'll dive into configuring Cloud Build to work with these triggers, incorporating crucial security elements like Secret Manager for handling sensitive credentials, setting up GitHub SSH keys for secure, and also setting up SSH keys to maintain secure access of your deployment on your GCP infrastructure and thus lead to seamless integration.
These steps eliminate the need for repetitive infrastructure setup with each code iteration, significantly reducing deployment overhead and enabling rapid, secure updates to your production environment.
Before jumping into the implementation, let's understand the concept of Continuous Deployment (CD) in the context of Git-based version control. CD is a DevOps practice where code changes are automatically built, tested, and deployed to production environments automatically. In the Google Cloud Platform (GCP) ecosystem, Cloud Build serves as a robust CI/CD tool that can ingest source code from diverse Version Control Systems (VCS) or cloud storage solutions, execute builds according to user-defined specifications, and generate deployment artifacts such as Docker images or Java ARchives (JARs).
Let's dive into setting up the whole CD pipeline now;
To implement GitHub triggers effectively, the initial step involves properly structuring and updating your repository with the latest codebase. It's absolutely necessary that the person configuring the Cloud Build trigger possesses the requisite permissions on the target repository. Specifically, they should have collaborator status or equivalent access rights to enable seamless integration between GitHub events and the deployment pipeline. This ensures that the CD system can respond to repository updates and initiate the deployment process.
Before proceeding with the setup, ensure that the Cloud Build API and the Secret Manager API are enabled in your Google Cloud environment. These can be activated via the Google Cloud Console's API Marketplace.
Establishing GitHub SSH keys for secure repository connection
For this, open up your cloud shell on your console and wait for it to connect. Now type in the following commands:
mkdir workingdir && cd workingdir
To generate your github key run this line replace the github-email with the email id that you have used to create your repository on Github
ssh-keygen -t rsa -b 4096 -N '' -f id_github -C github-email
This generates a 4096-bit RSA key pair without a passphrase, which is crucial, as Cloud Build doesn't support passphrase-protected keys.
Secure Private Key Storage on Secret Manager
Now after the above steps you would have a private and a public Github key. The private key (id_github) must be securely stored in Secret Manager to prevent unauthorized access. To do so follow these steps:
a. Navigate to the Secret Manager in Google Cloud Console.
b. Select 'Create Secret'.
c. Assign a descriptive name to the secret.
d. For the secret value, upload the 'id_github' file from your workingdir.
e. Maintain default region settings unless specific requirements dictate otherwise.
f. Finalize by clicking 'Create secret'
Once these steps are done you can be assured that your private key is protected and isn’t accessible to everyone.
Connecting to your Github repository
Now that you have your Git keys it is necessary to add the public key on GitHub so as to connect it to your infrastructure on GCP. So log into your GitHub account move into your repository page and follow these steps:
a. Move to the Settings tab of your repository
c. In the sidebar, select 'Deploy Keys' and click 'Add deploy key'.
d. Provide a descriptive title and paste the contents of 'workingdir/id_github.pub'. This is your public key
e. Enable 'Allow write access'.
f. Confirm by clicking 'Add key'.
Once you have added the Git keys to the Secret manager and your GitHub repository Access key section you can continue and remove the local copies. This adds another level of security and makes sure nobody else is able to access your GitHub key. To do so run this on your cloud shell:
rm id_github*
Configuring Cloud Build Service Account Permissions
Now that you have the above set you need to make sure that the Service Account that you are using has access to the Secret Manager.
a. Navigate to the Cloud Build Settings page in Google Cloud Console.
b. Select the service account for your build operations.
c. Enable the 'Secret Manager Secret Assessor' role for this account.
Preparing Known Hosts for GitHub
The 'known_hosts' file is a critical component of SSH security, playing a vital role in preventing man-in-the-middle (MITM) attacks. Therefore, the final step is to set up your known hosts file.
We save the GitHub public key for SSH verification in the known_hosts file. Go ahead use this command and create a known_hosts file in the working directory
ssh-keyscan -t rsa github.com > known_hosts.github
Make sure to download the 'known_hosts.github' file to the appropriate location in the build environment, in this case your Github repository.
With the GitHub SSH keys properly configured and securely stored, the next critical step is to create your cloudbuild.yaml configuration file. This YAML file defines the series of steps Cloud Build will execute during the deployment process.
For deploying applications to Compute Engine instances via SSH, it's imperative to set up authentication keys with the appropriate access permissions. These keys will enable Cloud Build to securely push code and execute commands on your Compute Engine Managed Instance Groups (MIGs).
In the next section, we'll delve into the details of setting up these SSH keys for Compute Engine. This final piece will complete our Continuous Deployment (CD) pipeline, enabling automated deployments to Compute Engine MIGs via SSH.
Configuring SSH keys for secure access to Compute Engine instances
This step is crucial for ensuring that our Cloud Build processes can securely interact with our deployment targets. Let's walk through this process, addressing common pitfalls and best practices along the way.
1. Generating SSH Keys
Create a folder named ssh_keys on your Cloud Editor. Inside that, create a blank text file called id_rsa.txt. This is where your SSH keys will be stored: both public and private.
Let's start by generating the SSH keys. Replace the italics values in the command below and run it on your cloud shell.
ssh-keygen -t rsa -f ~/enter_path_to_id_rsa.txt -C your_username -b 2048
The addition of 2048 generates a 2048-bit RSA key pair, which offers a good balance of security and performance.
2. Enter into your instance through the shell through the following command. Now the changes and the directories of files you make will all be saved in your instance memory. Make sure that you have allotted enough memory during instance formation or MIG template formation.
gcloud compute ssh username@instance_name --zone instance_zone
3. Adding SSH Keys to Compute Engine Metadata
Once you have your key pair, you need to add the public key to your Compute Engine instance's metadata. This allows you to access the SSH on that particular instance.This can be done using the following gcloud command paste this on the:
gcloud compute instances add-metadata instance_name \
--metadata ssh-keys="username:$(location_of_public_key/id_rsa.pub)" \
--zone instance_zone \
--project project_id
Replace the name of the instance with your compute engine instance name, followed by your username, location of public key, zone in which the instance is created and finally your project id.
4. Configuring the Instance for SSH Access
Now that you have added the public key to your instance metadata, in order to access the instance you would need to add the private key in the authorized_keys file in the instance ssh folder. This private key is verified with your public key from the metadata to give access to the ssh and further processing.
On your Compute Engine instance paste the following commands to set up the authorized_keys file:
mkdir -p ~/.ssh
nano ~/.ssh/authorized_keys
The nano command opens an editor. Paste your key in this file and then save it accordingly.
Next, let's set up the correct permissions for the keys, paste these commands in the shell:
chmod 700 ~/.ssh
chmod 600 ~/.ssh/authorized_keys
These permissions are crucial for security - SSH will refuse to work if the permissions are too open.
5. Testing Your SSH Connection
Once you have executed all the above steps your SSH connection should be set. You can test your SSH connection using the verbose flag to diagnose any issues:
ssh -v -i ~/ssh_keys/id_rsa username@external_ip_of_instance
These steps lead to the completion of your CD setup and you can seamlessly integrate your code on github to your production environment.
Before you are fully ready make sure that you have docker properly installed and running in your instance. An error commonly faced while handling docker are docker authentication issues.
COMMON ISSUE
If you encounter errors like 'Unauthenticated request' when pulling Docker images, you may need to add the appropriate IAM roles. Run this command to do so:
gcloud projects add-iam-policy-binding project_id \
--member=serviceAccount:service_account_name\
--role=roles/artifactregistry.reader
Also, configure Docker to authenticate with GCR:
gcloud auth configure-docker gcr.io --quiet
With these steps you are ready with your deployment pipeline along with continuous deployment pipeline and can seamlessly integrate updates directly from your github to production environment on the Google Cloud Platform.
There might be cases where the production code that you just deployed even after multiple checks might fail and you would want to return to the previous version. This can be taken care of by the rollback method in which you can return to the previous version on your deployed code. To do this you do have an option through the console where you can choose roll back. But if you do want to continue on shell and run it though there follow this command and replace it with the correct variables.
gcloud deploy targets rollback TARGET_NAME \ --delivery-pipeline= PIPELINE_NAME \ --release= RELEASE_NAME \ --rollout-id= ROLLOUT_ID
With this do make sure that deploying bugged code on production can lead to serious downtime on your application as well as loss of data so make sure that your code is fully tested and runs smoothly with traffic before pushing it to production.
Conclusion
The art of deploying applications on Google Cloud with a secure and automated CD pipeline is more than just a technical achievement—it's a step towards streamlined, efficient development. By meticulously configuring SSH keys and leveraging Git triggers, you ensure not only the integrity of your deployment process but also the speed and reliability of your updates. This approach eliminates manual errors, reduces operational overhead, and accelerates the delivery of new features to production.
As you continue refining your cloud infrastructure, the lessons from setting up this pipeline—such as securing credentials with Secret Manager and optimizing your GitHub integration—will serve as a strong foundation. With this setup, you're not just keeping up with the fast-paced world of DevOps; you're leading the charge towards a more secure, automated future.
FAQs
Some benefits of using cloud computing services include cost savings, scalability, flexibility, reliability, and increased collaboration.
Ankercloud takes data privacy and compliance seriously and adheres to industry best practices and standards to protect customer data. This includes implementing strong encryption, access controls, regular security audits, and compliance certifications such as ISO 27001, GDPR, and HIPAA, depending on the specific requirements of the customer. Learn More
The main types of cloud computing models are Infrastructure as a Service (IaaS), Platform as a Service (PaaS), and Software as a Service (SaaS). Each offers different levels of control and management for users.
Public clouds are owned and operated by third-party providers, private clouds are dedicated to a single organization, and hybrid clouds combine elements of both public and private clouds. The choice depends on factors like security requirements, scalability needs, and budget constraints.
Cloud computing services typically offer pay-as-you-go or subscription-based pricing models, where users only pay for the resources they consume. Prices may vary based on factors like usage, storage, data transfer, and additional features.
The process of migrating applications to the cloud depends on various factors, including the complexity of the application, the chosen cloud provider, and the desired deployment model. It typically involves assessing your current environment, selecting the appropriate cloud services, planning the migration strategy, testing and validating the migration, and finally, executing the migration with minimal downtime.
Ankercloud provides various levels of support to its customers, including technical support, account management, training, and documentation. Customers can access support through various channels such as email, phone, chat, and a self-service knowledge base.
The Ankercloud Team loves to listen