00 min read
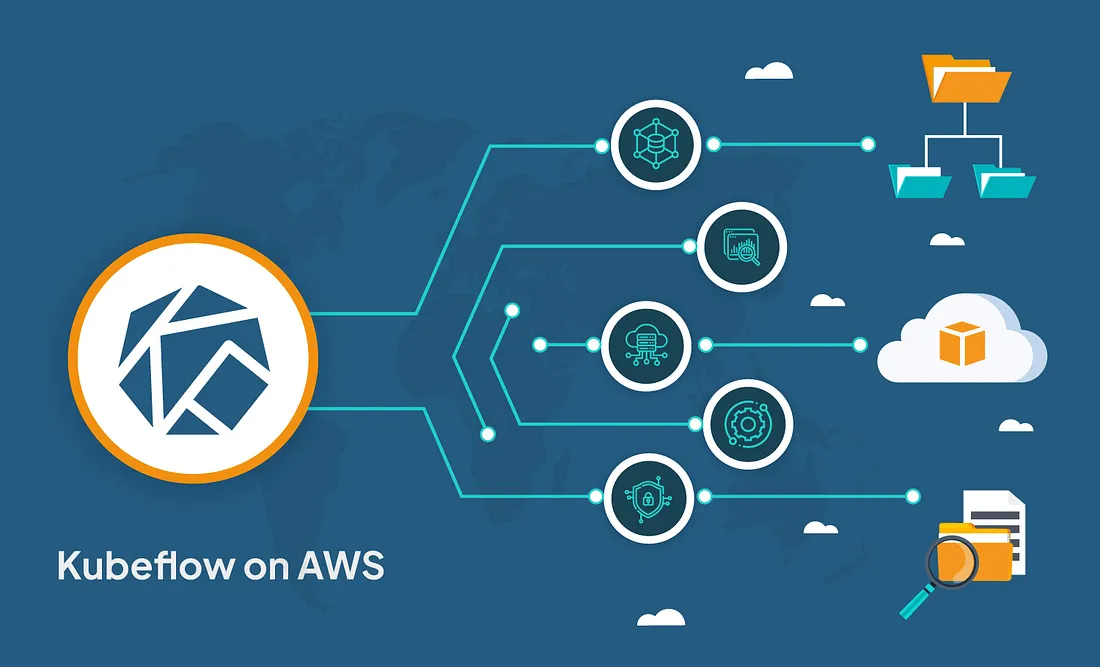
What is Kubeflow?
The Kubeflow project aims to simplify, portability, and scalability of machine learning (ML) workflow deployments on Kubernetes. Our objective is to make it simple to deploy best-of-breed open-source ML systems to a variety of infrastructures, not to replicate other services. Run Kubeflow wherever Kubernetes is installed and configured.
Need of Kubeflow?
The need for Kubeflow arises from the challenges of building, deploying, and managing machine learning workflows at scale. By providing a scalable, portable, reproducible, collaborative, and automated platform, Kubeflow enables organizations to accelerate their machine learning initiatives and improve their business outcomes.
Here are some of the main reasons why Kubeflow is needed:
Scalability: Machine learning workflows can be resource-intensive and require scaling up or down based on the size of the data and complexity of the model. Kubeflow allows you to scale your machine learning workflows based on your needs by leveraging the scalability and flexibility of Kubernetes.
Portability: Machine learning models often need to be deployed across multiple environments, such as development, staging, and production. Kubeflow provides a portable and consistent way to build, deploy, and manage machine learning workflows across different environments.
Reproducibility: Reproducibility is a critical aspect of machine learning, as it allows you to reproduce results and debug issues. Kubeflow provides a way to reproduce machine learning workflows by using containerization and version control.
Collaboration: Machine learning workflows often involve collaboration among multiple teams, including data scientists, developers, and DevOps engineers. Kubeflow provides a collaborative platform where teams can work together to build and deploy machine learning workflows.
Automation: Machine learning workflows involve multiple steps, including data preprocessing, model training, and model deployment. Kubeflow provides a way to automate these steps by defining pipelines that can be executed automatically or manually.
Architecture Diagram:
What does Kubeflow do?
Kubeflow provides a range of tools and frameworks to support the entire ML workflow, from data preparation to model training to deployment and monitoring. Here are some of the key components of Kubeflow:
Jupyter Notebooks: Kubeflow includes a Jupyter Notebook server that allows users to run Python code interactively and visualize data in real-time.
TensorFlow: Kubeflow includes TensorFlow, a popular open-source ML library, which can be used to train and deploy ML models.
TensorFlow Extended (TFX): TFX is an end-to-end ML platform for building and deploying production ML pipelines. Kubeflow integrates with TFX to provide a streamlined way to manage ML pipelines.
Katib: Kubeflow includes Katib, a framework for hyperparameter tuning and automated machine learning (AutoML).
Kubeflow Pipelines: Kubeflow Pipelines is a tool for building and deploying ML pipelines. It allows users to define complex workflows that can be run on a Kubernetes cluster.
What is Amazon SageMaker?
Amazon SageMaker is a fully-managed machine learning service that enables data scientists and developers to build, train, and deploy machine learning models at scale. Kubeflow, on the other hand, is an open-source machine learning platform that provides a framework for running machine learning workflows on Kubernetes.
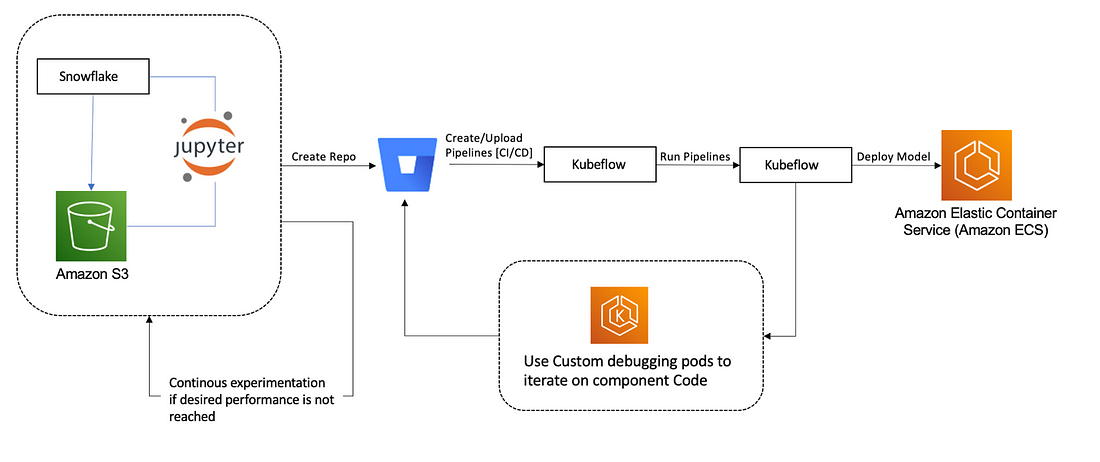
Using Amazon SageMaker with Kubeflow can help streamline the machine learning workflow by providing a unified platform for model development, training, and deployment. Here are the key steps to using Amazon SageMaker with Kubeflow:
Set up a Kubeflow cluster on Amazon EKS or other Kubernetes platforms.
● Install the Amazon SageMaker operator in your Kubeflow cluster. The operator provides a custom resource definition (CRD) that allows you to create and manage SageMaker resources within your Kubeflow environment.
● Use the SageMaker CRD to create SageMaker resources such as training jobs, model endpoints, and batch transform jobs within your Kubeflow cluster.
● Run your machine learning workflow using Kubeflow pipelines, which can orchestrate SageMaker training jobs and other components of the workflow.
● Monitor and manage your machine learning workflow using Kubeflow’s web-based UI or command-line tools.
● By integrating Amazon SageMaker with Kubeflow, you can take advantage of SageMaker’s powerful features for model training and deployment, while also benefiting from Kubeflow’s flexible and scalable machine learning platform.
Amazon SageMaker Components for Kubeflow Pipelines:
Component 1: Hyperparameter tuning job
The first component runs an Amazon SageMaker hyperparameter tuning job to optimize the following hyperparameters:
· learning-rate — [0.0001, 0.1] log scale
· optimizer — [sgd, adam]
· batch-size– [32, 128, 256]
· model-type — [resnet, custom model]
Component 2: Selecting the best hyperparameters
During the hyperparameter search in the previous step, models are only trained for 10 epochs to determine well-performing hyperparameters. In the second step, the best hyperparameters are taken and the epochs are updated to 80 to give the best hyperparameters an opportunity to deliver higher accuracy in the next step.
Component 3: Training job with the best hyperparameters
The third component runs an Amazon SageMaker training job using the best hyperparameters and for higher epochs.
Component 4: Creating a model for deployment
The fourth component creates an Amazon SageMaker model artifact.
Component 5: Deploying the inference endpoint
The final component deploys a model with Amazon SageMaker deployment.
Conclusion:
Kubeflow is an open-source platform that provides a range of tools and frameworks to make it easier to run ML workloads on Kubernetes. With Kubeflow, you can easily build and deploy ML models at scale, while also benefiting from the scalability, flexibility, and reproducibility of Kubernetes.
Kubeflow on AWS

What is Kubeflow?
The Kubeflow project aims to simplify, portability, and scalability of machine learning (ML) workflow deployments on Kubernetes. Our objective is to make it simple to deploy best-of-breed open-source ML systems to a variety of infrastructures, not to replicate other services. Run Kubeflow wherever Kubernetes is installed and configured.
Need of Kubeflow?
The need for Kubeflow arises from the challenges of building, deploying, and managing machine learning workflows at scale. By providing a scalable, portable, reproducible, collaborative, and automated platform, Kubeflow enables organizations to accelerate their machine learning initiatives and improve their business outcomes.
Here are some of the main reasons why Kubeflow is needed:
Scalability: Machine learning workflows can be resource-intensive and require scaling up or down based on the size of the data and complexity of the model. Kubeflow allows you to scale your machine learning workflows based on your needs by leveraging the scalability and flexibility of Kubernetes.
Portability: Machine learning models often need to be deployed across multiple environments, such as development, staging, and production. Kubeflow provides a portable and consistent way to build, deploy, and manage machine learning workflows across different environments.
Reproducibility: Reproducibility is a critical aspect of machine learning, as it allows you to reproduce results and debug issues. Kubeflow provides a way to reproduce machine learning workflows by using containerization and version control.
Collaboration: Machine learning workflows often involve collaboration among multiple teams, including data scientists, developers, and DevOps engineers. Kubeflow provides a collaborative platform where teams can work together to build and deploy machine learning workflows.
Automation: Machine learning workflows involve multiple steps, including data preprocessing, model training, and model deployment. Kubeflow provides a way to automate these steps by defining pipelines that can be executed automatically or manually.
Architecture Diagram:
What does Kubeflow do?
Kubeflow provides a range of tools and frameworks to support the entire ML workflow, from data preparation to model training to deployment and monitoring. Here are some of the key components of Kubeflow:
Jupyter Notebooks: Kubeflow includes a Jupyter Notebook server that allows users to run Python code interactively and visualize data in real-time.
TensorFlow: Kubeflow includes TensorFlow, a popular open-source ML library, which can be used to train and deploy ML models.
TensorFlow Extended (TFX): TFX is an end-to-end ML platform for building and deploying production ML pipelines. Kubeflow integrates with TFX to provide a streamlined way to manage ML pipelines.
Katib: Kubeflow includes Katib, a framework for hyperparameter tuning and automated machine learning (AutoML).
Kubeflow Pipelines: Kubeflow Pipelines is a tool for building and deploying ML pipelines. It allows users to define complex workflows that can be run on a Kubernetes cluster.
What is Amazon SageMaker?
Amazon SageMaker is a fully-managed machine learning service that enables data scientists and developers to build, train, and deploy machine learning models at scale. Kubeflow, on the other hand, is an open-source machine learning platform that provides a framework for running machine learning workflows on Kubernetes.
Using Amazon SageMaker with Kubeflow can help streamline the machine learning workflow by providing a unified platform for model development, training, and deployment. Here are the key steps to using Amazon SageMaker with Kubeflow:
Set up a Kubeflow cluster on Amazon EKS or other Kubernetes platforms.
● Install the Amazon SageMaker operator in your Kubeflow cluster. The operator provides a custom resource definition (CRD) that allows you to create and manage SageMaker resources within your Kubeflow environment.
● Use the SageMaker CRD to create SageMaker resources such as training jobs, model endpoints, and batch transform jobs within your Kubeflow cluster.
● Run your machine learning workflow using Kubeflow pipelines, which can orchestrate SageMaker training jobs and other components of the workflow.
● Monitor and manage your machine learning workflow using Kubeflow’s web-based UI or command-line tools.
● By integrating Amazon SageMaker with Kubeflow, you can take advantage of SageMaker’s powerful features for model training and deployment, while also benefiting from Kubeflow’s flexible and scalable machine learning platform.
Amazon SageMaker Components for Kubeflow Pipelines:
Component 1: Hyperparameter tuning job
The first component runs an Amazon SageMaker hyperparameter tuning job to optimize the following hyperparameters:
· learning-rate — [0.0001, 0.1] log scale
· optimizer — [sgd, adam]
· batch-size– [32, 128, 256]
· model-type — [resnet, custom model]
Component 2: Selecting the best hyperparameters
During the hyperparameter search in the previous step, models are only trained for 10 epochs to determine well-performing hyperparameters. In the second step, the best hyperparameters are taken and the epochs are updated to 80 to give the best hyperparameters an opportunity to deliver higher accuracy in the next step.
Component 3: Training job with the best hyperparameters
The third component runs an Amazon SageMaker training job using the best hyperparameters and for higher epochs.
Component 4: Creating a model for deployment
The fourth component creates an Amazon SageMaker model artifact.
Component 5: Deploying the inference endpoint
The final component deploys a model with Amazon SageMaker deployment.
Conclusion:
Kubeflow is an open-source platform that provides a range of tools and frameworks to make it easier to run ML workloads on Kubernetes. With Kubeflow, you can easily build and deploy ML models at scale, while also benefiting from the scalability, flexibility, and reproducibility of Kubernetes.