AI/Machine Learning for Workplace Safety

Automating the recognition of personal protective equipment to
increase safety in the workplace
About the Ankercloud solution
Risk sources are present in all working environments and take many different forms, including sharp edges, falling objects, sparks, chemicals, noise and countless other potentially dangerous situations.
Safety authorities such as the European Commission often require companies to protect their employees and customers from the risk of injury by providing and ensuring the use of personal protective equipment (PPE).

Safety in the workplace is usually a top priority in various industries such as manufacturing, food processing, chemicals, healthcare, construction and logistics. However, despite their efforts to follow PPE guidelines, employees may inadvertently forget to wear it or not realise that it is required in certain areas.
This poses potential risks to their safety and can cause compliance issues for organizations. Today, organizations have to rely on supervisors to monitor individuals in certain areas and remind them to use PPE, but this is neither reliable nor cost-effective.
Automated PPE Detection Solution
Revolutionize safety protocols with our automated PPE detection system. Utilize camera image analysis to ensure compliance, minimize risk, and bolster safety practices across multiple locations. Ankercloud's BI-in-the-Box for Manufacturing provides comprehensive reporting for proactive safety measures.
Automate PPE detection at scale
Optimize your manual inspections by automatically detecting PPE. Use image analysis from cameras on site to determine whether employees and customers are wearing the required protective equipment.

Reduce the risk for humans and finances
Enhance manual monitoring with automated PPE detection. Use image analysis from on-site cameras at your locations to determine whether employees and customers are complying with recommended PPE policies.

Improve safety practices
Capture and analyze the results of PPE detection for the various workplaces, locations and operating sites in order to prioritize additional safety measures such as warning signs or training. Ankercloud's BI-in-the-Box for Manufacturing can be used to generate detailed reports on PSA detection.


PPE Compliance Monitoring
With the Ankercloud solution, you have the ability to analyze images from your cameras across all sites to automatically determine whether people in the images are wearing the required PPE, such as masks, badges, gloves, head protection, high-visibility vests or safety goggles.
In addition, you can collect the results and analyze them by time and location to determine how safety instructions or training can be improved. Reports can also be generated to support regulatory audits. This feature does not perform facial analyses or comparisons and is not able to identify or match the identity of captured individuals.







SUCCESS STORIES
Our Customers Stories

High Performance Computing using Parallel Cluster, Infrastructure Set-up


gocomo Migrates Social Data Platform to AWS for Performance & Scalability with Ankercloud


Migration a Saas platform from On-Prem to GCP


Benchmarking AWS performance to run environmental simulations over Belgium
.jpg)
Ankercloud: Partners with AWS, GCP, and Azure
We excel through partnerships with industry giants like AWS, GCP, and Azure, offering innovative solutions backed by leading cloud technologies.



Check out our blog

Enhancing DDoS Protection with Extended IP Block Duration Using AWS WAF Rate-Based Rules
Problem
DDoS attackers use the same IPs to send many HTTP requests once the AWS WAF rate limit rule removes the block. The default block lasts only for a definite time, so attacks repeat again. We need a solution that makes the block time for harmful IPs last indefinitely, keeping them blocked until the attack persists.
Solution Workflow
- CloudFormation: Use the predefined CFT template to set custom block time for harmful IPs. Adjust by how severe the attack is.
- EventBridge & Lambda: Let EventBridge call a Lambda function every minute. The function checks AWS WAF’s rate rule for blocked IPs.
- Store in S3: Save blocked IPs in an S3 bucket with timestamps for records.
- Update WAF Custom IP Sets: Lambda revises WAF custom IP sets by keeping IPs within block time. It also drops IPs that passed the block period.
- Regular Updates: Run the process every minute to keep only harmful IPs blocked and avoid an outdated, heavy block list.
Deploying the Solution
- Download the CloudFormation Template:
Download the customized AWS CloudFormation template (customized-block-period-template.yaml) from the solution’s GitHub repository. - Create a Stack in CloudFormation Console:
Open the AWS CloudFormation console, then create a new stack with the downloaded template. Check the CloudFormation User Guide for detailed instructions for stack creation.
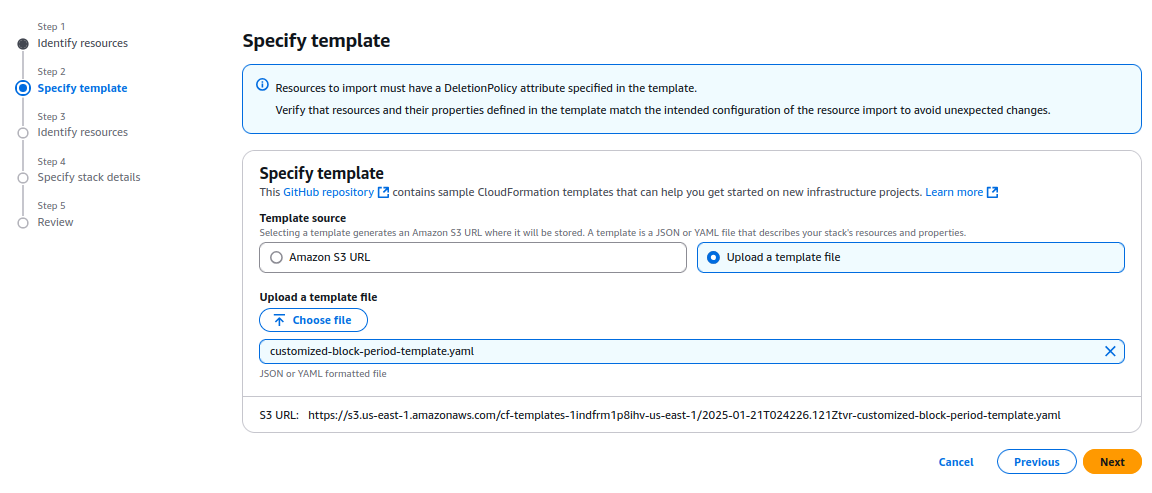
- Specify Stack Details:
On the Specify Stack Details page, type a unique stack name. Enter the required parameters, such as blocking duration and configuration settings listed in the prerequisites.
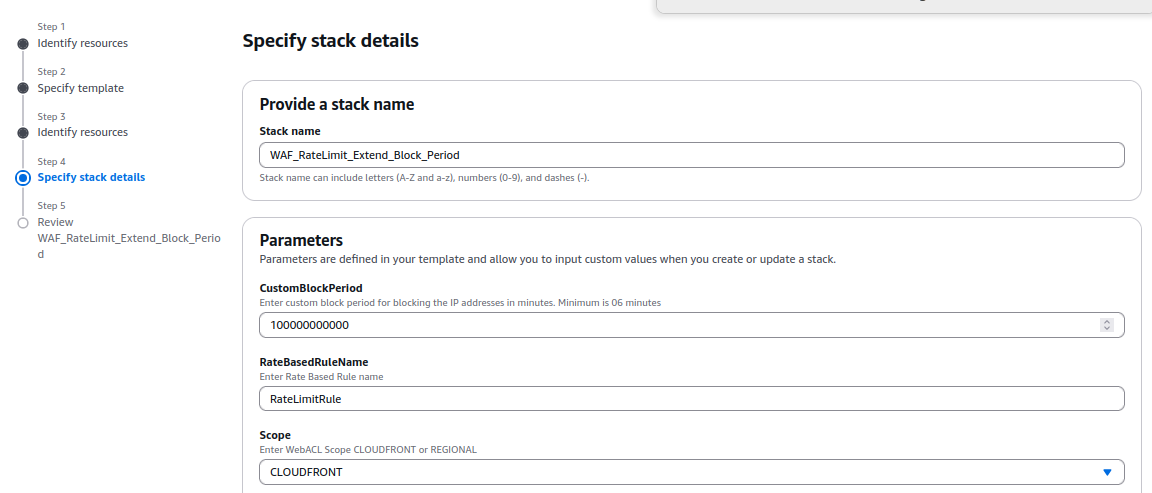
- Provisioning Resources:
The template provisions several AWS resources, including:
- AWS WAF IP Sets, which store the blocked IPs.
- An Amazon EventBridge Rule that triggers the Lambda function at regular intervals.
- Amazon S3 Buckets to store the blocked IP addresses and their timestamps.
- AWS IAM Roles with permissions to allow Lambda functions to query AWS WAF and access other required resources.
- The AWS Lambda function itself, which performs the logic for tracking and updating the blocked IP addresses.
- Deploy and Apply the WAF Rule:
Deployment takes under 15 minutes. When the stack shows CREATE_COMPLETE, build a custom AWS WAF rule to apply custom IP sets and block the malicious IPs.
%20(1).png)
6. Reviewing IPs that are Blocked:
Go to the IP Sets section on the AWS WAF console. Choose the set named with the prefix "IPv4-IPset." You can check the list of IPs blocked by the rate limit rule in the set produced by the stack.
7. Whitelisting or Removing Specific IPs from the Blocked List
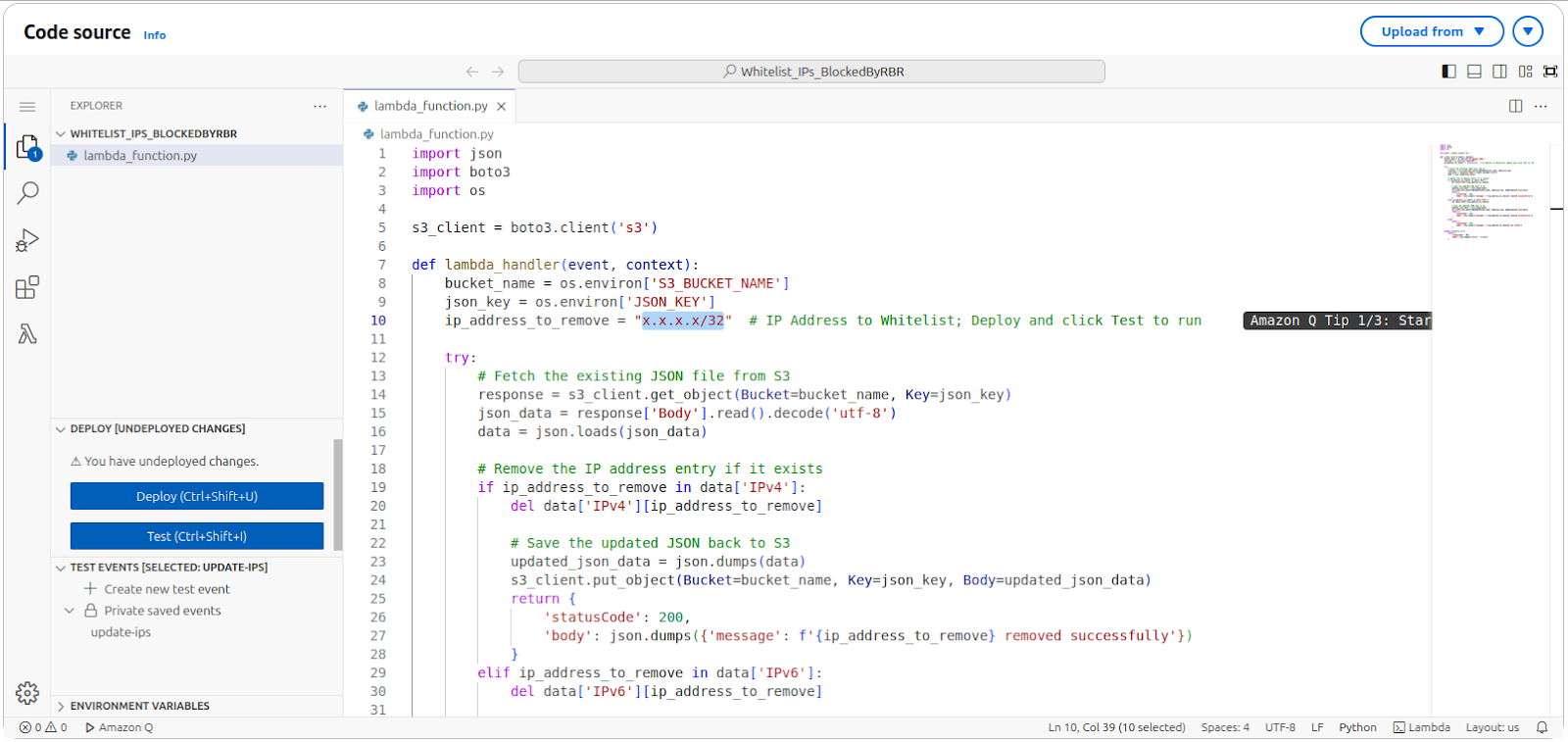
To remove an IP from the blocked list, merely deleting it from the IP set in the AWS WAF console does not work. This is because the IP set updates every minute with a JSON file stored in an S3 bucket (controlled by the CloudFormation template).
To remove an IP properly, delete it from the JSON file; then upload the revised file to the S3 bucket. You may use a Lambda script to automate this process. The script lets you choose the IP to remove; it completes each required step.
You can find the environment variable details and the Python code for the script here:
Blocking Requests Originating from Referrer URLs
Problem Statement:
Third-party websites might copy images or content from your site and use them on their platforms. These requests come via referrer URLs.
Solution:
To block such requests, follow these steps:
- Identify the Referrer URL:
- Open the site suspected of scraping your content in a browser.
- Right-click on the page and select Inspect to open the developer tools.
- Navigate to the Network tab and reload the page.
- Look for requests made to your site. For example, if the site https://www.webpagetest.org/ is scraping your images, you might find requests to your domain in the list.
- Identify the image being used (e.g., twitter.svg), and click on the request.
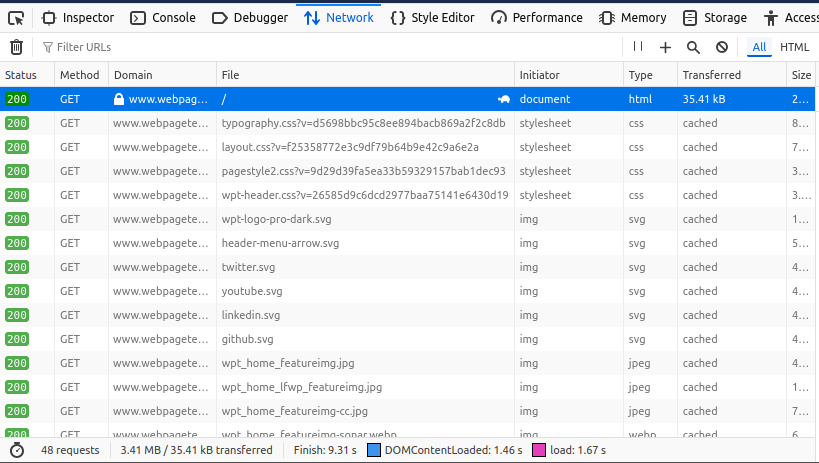
- Retrieve the Referrer URL:
- In the request details on the right panel, locate the Headers section.
- Scroll to find the Referer value. This will show the URL of the site making the request (e.g., https://www.webpagetest.org/).
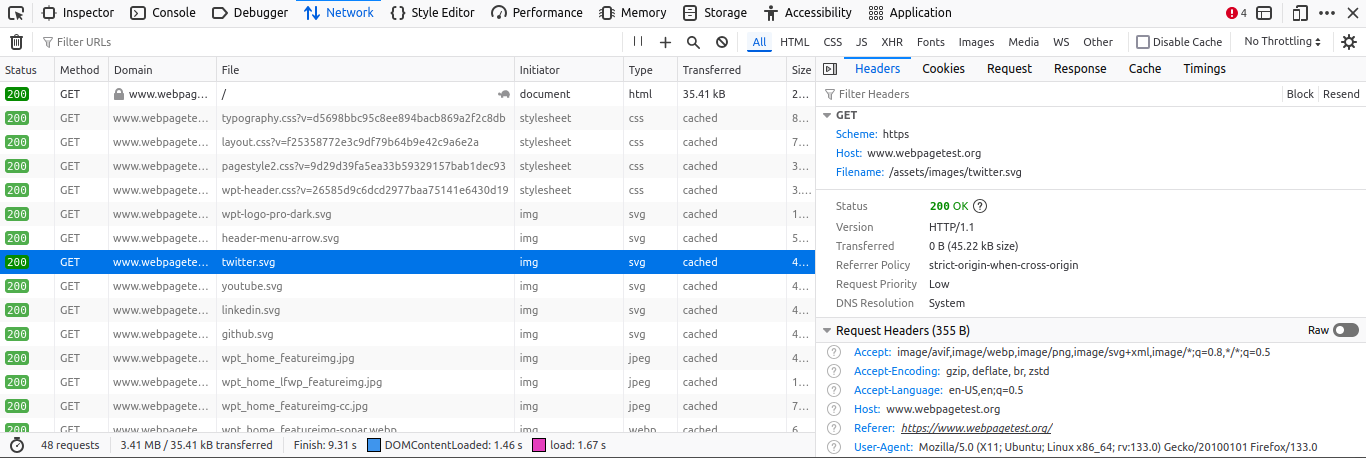
- Block the Referrer in AWS WAF:
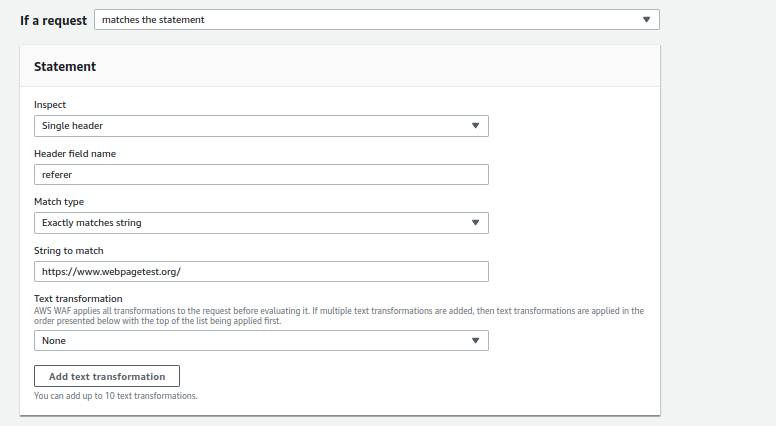
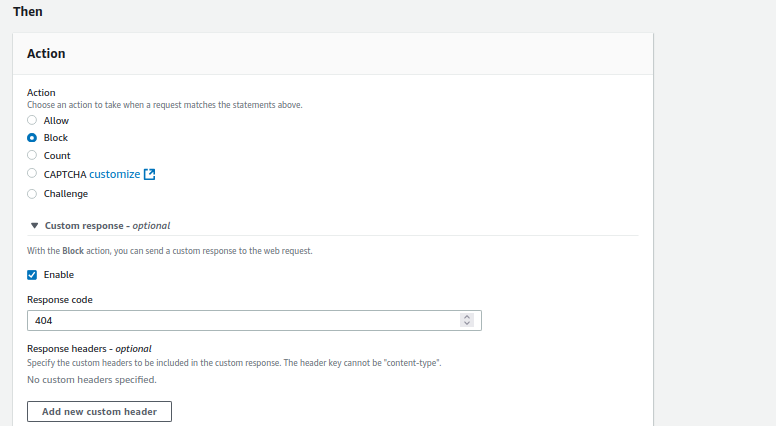
- Open the AWS WAF console and create a new Custom Rule.
- Set the Inspect field to Single Header.
- Use Referer as the Header Field Name.
- Set Match Type to Exactly matches string.
- Enter the referrer URL (e.g., https://www.webpagetest.org/) in the String to Match field.
- Set the Action to Block. You can optionally configure a custom response code for blocked requests.
Outcome
By enforcing this rule, you can block requests from specific referrer URLs stopping site mirroring and web scraping by third-party sites.
2
.png)
Automating AWS Amplify: Streamlining CI/CD with Shell & Expect Scripts
Introduction
Automating cloud infrastructure and deployments is a crucial aspect of DevOps. AWS Amplify provides a powerful framework for developing and deploying full-stack applications. However, initializing and managing an Amplify app manually can be time-consuming, especially when integrating it into a CI/CD pipeline like Jenkins.
This blog explores how we automated the Amplify app creation process in headless mode using shell scripting and Expect scripts, eliminating interactive prompts to streamline our pipeline.
Setting Up AWS and Amplify CLI
1. Configure AWS Credentials
Before initializing an Amplify app, configure AWS CLI with your Access Key and Secret Key:
aws configure
2. Install and Configure Amplify CLI
To install Amplify CLI and configure it:
npm install -g @aws-amplify/cli
amplify configure
This will prompt you to create an IAM user and set up authentication.
Automating Amplify App Creation
1. Initialize the Amplify App Using a Script
We created a shell script amplify-init.sh to automate the initialization process.
amplify-init.sh
#!/bin/bash
set -e
IFS='|'
AMPLIFY_NAME=amplifyapp
API_FOLDER_NAME=amplifyapp
BACKEND_ENV_NAME=staging
AWS_PROFILE=default
REGION=us-east-1
AWSCLOUDFORMATIONCONFIG="{\
\"configLevel\":\"project\",\
\"useProfile\":true,\
\"profileName\":\"${AWS_PROFILE}\",\
\"region\":\"${REGION}\"\
}"
AMPLIFY="{\
\"projectName\":\"${AMPLIFY_NAME}\",\
\"envName\":\"${BACKEND_ENV_NAME}\",\
\"defaultEditor\":\"Visual Studio Code\"\
}"
amplify init --amplify $AMPLIFY --providers $AWSCLOUDFORMATIONCONFIG --yes
Run the script:
./amplify-init.sh
2. Automating API and Storage Integration
Since Amplify prompts users for inputs, we used Expect scripts to automate API and storage creation.
add-api-response.exp
#!/usr/bin/expect
spawn ./add-api.sh
expect "? Please select from one of the below mentioned services:\r"
send -- "GraphQL\r"
expect eof
add-storage-response.exp
#!/usr/bin/expect
spawn ./add-storage.sh
expect "? Select from one of the below mentioned services:\r"
send -- "Content\r"
expect eof
These scripts eliminate manual input, making Amplify API and storage additions fully automated.
Automating Schema Updates
One of the biggest challenges was automating schema.graphql updates without manual intervention. The usual approach required engineers to manually upload the file, leading to potential errors.
To solve this, we automated the process with an Amplify Pull script.
amplify-pull.sh
#!/bin/bash
set -e
IFS='|'
AMPLIFY_NAME=amp3
API_FOLDER_NAME=amp3
BACKEND_ENV_NAME=prod
AWS_PROFILE=default
REGION=us-east-1
APP_ID=dzvchzih477u2
AWSCLOUDFORMATIONCONFIG="{\
\"configLevel\":\"project\",\
\"useProfile\":true,\
\"profileName\":\"${AWS_PROFILE}\",\
\"region\":\"${REGION}\"\
}"
AMPLIFY="{\
\"projectName\":\"${AMPLIFY_NAME}\",\
\"appId\":\"${APP_ID}\",\
\"envName\":\"${BACKEND_ENV_NAME}\",\
\"defaultEditor\":\"code\"\
}"
amplify pull --amplify $AMPLIFY --providers $AWSCLOUDFORMATIONCONFIG --yes
This script ensures that the latest schema changes are pulled and updated in the pipeline automatically.
Integrating with Jenkins
Since this automation was integrated with a Jenkins pipeline, we enabled "This project is parameterized" to allow file uploads directly into the workspace.
- Upload the schema.graphql file via Jenkins UI.
- The script pulls the latest changes and updates Amplify automatically.
This method eliminates manual intervention, ensuring consistency in schema updates across multiple environments.
Conclusion
By automating AWS Amplify workflows with shell scripting and Expect scripts, we achieved: Fully automated Amplify app creation
Eliminated manual schema updates
Seamless integration with Jenkins pipelines
Faster deployments with reduced errors
This approach significantly minimized manual effort, ensuring that updates were streamlined and efficient. If you're using Amplify for your projects, automation like this can save countless hours and improve developer productivity.
Have questions or feedback? Drop a comment below!
2
.png)
Configuring GKE Ingress: Traffic Routing, Security, and Load Balancing
GKE Ingress acts as a bridge between external users and your Kubernetes services. It allows you to define rules for routing traffic based on hostnames and URL paths, enabling you to direct requests to different backend services seamlessly.
A single GKE Ingress controller routes traffic to multiple services by identifying the target backend based on hostname and URL paths. It supports multiple certificates for different domains.
FrontendConfig enables automatic redirection from HTTP to HTTPS, ensuring encrypted communication between the web browser and the Ingress.
BackendConfig that allows you to configure advanced settings for backend services. It provides additional options beyond standard service configurations, enabling better control over traffic handling, security, and load balancing behavior.
Setup GKE ingress with application loadbalancer
To specify an Ingress class, you must use the kubernetes.io/ingress.class annotation.The “gce” class deploys an external Application Load Balancer
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: my-ingress
annotations:
kubernetes.io/ingress.class: “gce”
Configure FrontendConfiguration:
apiVersion: networking.gke.io/v1beta1
kind: FrontendConfig
metadata:
name: my-frontend-config
spec:
redirectToHttps:
enabled: true
The FrontendConfig resource in GKE enables automatic redirection from HTTP to HTTPS, ensuring secure communication between clients and services.
Associating FrontendConfig with your Ingress
You can associate a FrontendConfig with an Ingress. Use the “networking.gke.io/v1beta1.FrontendConfig” to annotate with the ingress.
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
networking.gke.io/v1beta1.FrontendConfig: “my-frontend-config”
Configure Backend Configuration:
apiVersion: cloud.google.com/v1
kind: BackendConfig
metadata:
name: my-backendconfig
spec:
timeoutSec: 40
BackendConfig to set a backend service timeout period in seconds.The following BackendConfig manifest specifies a timeout of 40 seconds.
Associate the backend configuration with service:
apiVersion: v1
kind: Service
metadata:
annotations:
cloud.google.com/backend-config: ‘{“ports”:{“my-backendconfig”}}’
cloud.google.com/neg: ‘{“ingress”: true}’
spec:
ports:
- name: app
port: 80
protocol: TCP
targetPort: 50000
We can specify a custom BackendConfig for one or more ports using a key that matches the port’s name or number. The Ingress controller uses the specific BackendConfig when it creates a load balancer backend service for a referenced Service port.
Creating an Ingress with a Google-Managed SSL Certificate
To set up a Google-managed SSL certificate and link it to an Ingress, follow these steps:
- Create a ManagedCertificate resource in the same namespace as the Ingress.
- Associate the ManagedCertificate with the Ingress by adding the annotation networking.gke.io/managed-certificates to the Ingress resource.
apiVersion: networking.gke.io/v1
kind: ManagedCertificate
metadata:
name: managed-cert
spec:
domains:
- hello.example.com
- world.example.com
Associate the SSL with Ingress
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress
annotations:
networking.gke.io/v1beta1.FrontendConfig: “my-frontend-config”
networking.gke.io/managed-certificates: managed-cert
kubernetes.io/ingress.class: “gce”
associate it with the managed-certificate by adding an annotation.
Assign Static IP to Ingress
When hosting a web server on a domain, the application’s external IP address should be static to ensure it remains unchanged.
By default, GKE assigns ephemeral external IP addresses for HTTP applications exposed via an Ingress. However, these addresses can change over time. If you intend to run your application long-term, it is essential to use a static external IP address for stability.
Create a global static ip from gcp console with specific name eg: web-static-ip and associate it with ingress by adding the global-static-ip-name annotation.
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress
annotations:
networking.gke.io/v1beta1.FrontendConfig: “my-frontend-config”
networking.gke.io/managed-certificates: managed-cert
kubernetes.io/ingress.class: “gce”
kubernetes.io/ingress.global-static-ip-name: “web-static-ip”
Google Cloud Armor Ingress security policy
Google Cloud Armor security policies safeguard your load-balanced applications against web-based attacks. Once configured, a security policy can be referenced in a BackendConfig to apply protection to specific backends.
To enable a security policy, add its name to the BackendConfig. The following example configures a security policy named security-policy:
apiVersion: cloud.google.com/v1
kind: BackendConfig
metadata:
namespace: cloud-armor-how-to
name: my-backendconfig
spec:
securityPolicy:
name: “security-policy”
User-defined request/response headers
A BackendConfig can be used to define custom request headers that the load balancer appends to requests before forwarding them to the backend services.
These custom headers are only added to client requests and not to health check probes. If a backend requires a specific header for authorization and it is absent in the health check request, the health check may fail.
To configure user-defined request headers, specify them under the customRequestHeaders/customResponseHeaders property in the BackendConfig resource. Each header should be defined as a header-name:header-value string.
apiVersion: cloud.google.com/v1
kind: BackendConfig
metadata:
name: my-backendconfig
spec:
customRequestHeaders:
headers:
- “X-Client-Region:{client_region}”
- “X-Client-City:{client_city}”
- “X-Client-CityLatLong:{client_city_lat_long}”
apiVersion: cloud.google.com/v1
kind: BackendConfig
metadata:
name: my-backendconfig
spec:
customResponseHeaders:
headers:
- “Strict-Transport-Security: max-age=28800; includeSubDomains”
2
Enhancing DDoS Protection with Extended IP Block Duration Using AWS WAF Rate-Based Rules
Problem
DDoS attackers use the same IPs to send many HTTP requests once the AWS WAF rate limit rule removes the block. The default block lasts only for a definite time, so attacks repeat again. We need a solution that makes the block time for harmful IPs last indefinitely, keeping them blocked until the attack persists.
Solution Workflow
- CloudFormation: Use the predefined CFT template to set custom block time for harmful IPs. Adjust by how severe the attack is.
- EventBridge & Lambda: Let EventBridge call a Lambda function every minute. The function checks AWS WAF’s rate rule for blocked IPs.
- Store in S3: Save blocked IPs in an S3 bucket with timestamps for records.
- Update WAF Custom IP Sets: Lambda revises WAF custom IP sets by keeping IPs within block time. It also drops IPs that passed the block period.
- Regular Updates: Run the process every minute to keep only harmful IPs blocked and avoid an outdated, heavy block list.
Deploying the Solution
- Download the CloudFormation Template:
Download the customized AWS CloudFormation template (customized-block-period-template.yaml) from the solution’s GitHub repository. - Create a Stack in CloudFormation Console:
Open the AWS CloudFormation console, then create a new stack with the downloaded template. Check the CloudFormation User Guide for detailed instructions for stack creation.
- Specify Stack Details:
On the Specify Stack Details page, type a unique stack name. Enter the required parameters, such as blocking duration and configuration settings listed in the prerequisites.
- Provisioning Resources:
The template provisions several AWS resources, including:
- AWS WAF IP Sets, which store the blocked IPs.
- An Amazon EventBridge Rule that triggers the Lambda function at regular intervals.
- Amazon S3 Buckets to store the blocked IP addresses and their timestamps.
- AWS IAM Roles with permissions to allow Lambda functions to query AWS WAF and access other required resources.
- The AWS Lambda function itself, which performs the logic for tracking and updating the blocked IP addresses.
- Deploy and Apply the WAF Rule:
Deployment takes under 15 minutes. When the stack shows CREATE_COMPLETE, build a custom AWS WAF rule to apply custom IP sets and block the malicious IPs.
6. Reviewing IPs that are Blocked:
Go to the IP Sets section on the AWS WAF console. Choose the set named with the prefix "IPv4-IPset." You can check the list of IPs blocked by the rate limit rule in the set produced by the stack.
7. Whitelisting or Removing Specific IPs from the Blocked List
To remove an IP from the blocked list, merely deleting it from the IP set in the AWS WAF console does not work. This is because the IP set updates every minute with a JSON file stored in an S3 bucket (controlled by the CloudFormation template).
To remove an IP properly, delete it from the JSON file; then upload the revised file to the S3 bucket. You may use a Lambda script to automate this process. The script lets you choose the IP to remove; it completes each required step.
You can find the environment variable details and the Python code for the script here:
Blocking Requests Originating from Referrer URLs
Problem Statement:
Third-party websites might copy images or content from your site and use them on their platforms. These requests come via referrer URLs.
Solution:
To block such requests, follow these steps:
- Identify the Referrer URL:
- Open the site suspected of scraping your content in a browser.
- Right-click on the page and select Inspect to open the developer tools.
- Navigate to the Network tab and reload the page.
- Look for requests made to your site. For example, if the site https://www.webpagetest.org/ is scraping your images, you might find requests to your domain in the list.
- Identify the image being used (e.g., twitter.svg), and click on the request.
- Retrieve the Referrer URL:
- In the request details on the right panel, locate the Headers section.
- Scroll to find the Referer value. This will show the URL of the site making the request (e.g., https://www.webpagetest.org/).
- Block the Referrer in AWS WAF:
- Open the AWS WAF console and create a new Custom Rule.
- Set the Inspect field to Single Header.
- Use Referer as the Header Field Name.
- Set Match Type to Exactly matches string.
- Enter the referrer URL (e.g., https://www.webpagetest.org/) in the String to Match field.
- Set the Action to Block. You can optionally configure a custom response code for blocked requests.
Outcome
By enforcing this rule, you can block requests from specific referrer URLs stopping site mirroring and web scraping by third-party sites.
Automating AWS Amplify: Streamlining CI/CD with Shell & Expect Scripts
Introduction
Automating cloud infrastructure and deployments is a crucial aspect of DevOps. AWS Amplify provides a powerful framework for developing and deploying full-stack applications. However, initializing and managing an Amplify app manually can be time-consuming, especially when integrating it into a CI/CD pipeline like Jenkins.
This blog explores how we automated the Amplify app creation process in headless mode using shell scripting and Expect scripts, eliminating interactive prompts to streamline our pipeline.
Setting Up AWS and Amplify CLI
1. Configure AWS Credentials
Before initializing an Amplify app, configure AWS CLI with your Access Key and Secret Key:
aws configure
2. Install and Configure Amplify CLI
To install Amplify CLI and configure it:
npm install -g @aws-amplify/cli
amplify configure
This will prompt you to create an IAM user and set up authentication.
Automating Amplify App Creation
1. Initialize the Amplify App Using a Script
We created a shell script amplify-init.sh to automate the initialization process.
amplify-init.sh
#!/bin/bash
set -e
IFS='|'
AMPLIFY_NAME=amplifyapp
API_FOLDER_NAME=amplifyapp
BACKEND_ENV_NAME=staging
AWS_PROFILE=default
REGION=us-east-1
AWSCLOUDFORMATIONCONFIG="{\
\"configLevel\":\"project\",\
\"useProfile\":true,\
\"profileName\":\"${AWS_PROFILE}\",\
\"region\":\"${REGION}\"\
}"
AMPLIFY="{\
\"projectName\":\"${AMPLIFY_NAME}\",\
\"envName\":\"${BACKEND_ENV_NAME}\",\
\"defaultEditor\":\"Visual Studio Code\"\
}"
amplify init --amplify $AMPLIFY --providers $AWSCLOUDFORMATIONCONFIG --yes
Run the script:
./amplify-init.sh
2. Automating API and Storage Integration
Since Amplify prompts users for inputs, we used Expect scripts to automate API and storage creation.
add-api-response.exp
#!/usr/bin/expect
spawn ./add-api.sh
expect "? Please select from one of the below mentioned services:\r"
send -- "GraphQL\r"
expect eof
add-storage-response.exp
#!/usr/bin/expect
spawn ./add-storage.sh
expect "? Select from one of the below mentioned services:\r"
send -- "Content\r"
expect eof
These scripts eliminate manual input, making Amplify API and storage additions fully automated.
Automating Schema Updates
One of the biggest challenges was automating schema.graphql updates without manual intervention. The usual approach required engineers to manually upload the file, leading to potential errors.
To solve this, we automated the process with an Amplify Pull script.
amplify-pull.sh
#!/bin/bash
set -e
IFS='|'
AMPLIFY_NAME=amp3
API_FOLDER_NAME=amp3
BACKEND_ENV_NAME=prod
AWS_PROFILE=default
REGION=us-east-1
APP_ID=dzvchzih477u2
AWSCLOUDFORMATIONCONFIG="{\
\"configLevel\":\"project\",\
\"useProfile\":true,\
\"profileName\":\"${AWS_PROFILE}\",\
\"region\":\"${REGION}\"\
}"
AMPLIFY="{\
\"projectName\":\"${AMPLIFY_NAME}\",\
\"appId\":\"${APP_ID}\",\
\"envName\":\"${BACKEND_ENV_NAME}\",\
\"defaultEditor\":\"code\"\
}"
amplify pull --amplify $AMPLIFY --providers $AWSCLOUDFORMATIONCONFIG --yes
This script ensures that the latest schema changes are pulled and updated in the pipeline automatically.
Integrating with Jenkins
Since this automation was integrated with a Jenkins pipeline, we enabled "This project is parameterized" to allow file uploads directly into the workspace.
- Upload the schema.graphql file via Jenkins UI.
- The script pulls the latest changes and updates Amplify automatically.
This method eliminates manual intervention, ensuring consistency in schema updates across multiple environments.
Conclusion
By automating AWS Amplify workflows with shell scripting and Expect scripts, we achieved: Fully automated Amplify app creation
Eliminated manual schema updates
Seamless integration with Jenkins pipelines
Faster deployments with reduced errors
This approach significantly minimized manual effort, ensuring that updates were streamlined and efficient. If you're using Amplify for your projects, automation like this can save countless hours and improve developer productivity.
Have questions or feedback? Drop a comment below!
Configuring GKE Ingress: Traffic Routing, Security, and Load Balancing
GKE Ingress acts as a bridge between external users and your Kubernetes services. It allows you to define rules for routing traffic based on hostnames and URL paths, enabling you to direct requests to different backend services seamlessly.
A single GKE Ingress controller routes traffic to multiple services by identifying the target backend based on hostname and URL paths. It supports multiple certificates for different domains.
FrontendConfig enables automatic redirection from HTTP to HTTPS, ensuring encrypted communication between the web browser and the Ingress.
BackendConfig that allows you to configure advanced settings for backend services. It provides additional options beyond standard service configurations, enabling better control over traffic handling, security, and load balancing behavior.
Setup GKE ingress with application loadbalancer
To specify an Ingress class, you must use the kubernetes.io/ingress.class annotation.The “gce” class deploys an external Application Load Balancer
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: my-ingress
annotations:
kubernetes.io/ingress.class: “gce”
Configure FrontendConfiguration:
apiVersion: networking.gke.io/v1beta1
kind: FrontendConfig
metadata:
name: my-frontend-config
spec:
redirectToHttps:
enabled: true
The FrontendConfig resource in GKE enables automatic redirection from HTTP to HTTPS, ensuring secure communication between clients and services.
Associating FrontendConfig with your Ingress
You can associate a FrontendConfig with an Ingress. Use the “networking.gke.io/v1beta1.FrontendConfig” to annotate with the ingress.
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
networking.gke.io/v1beta1.FrontendConfig: “my-frontend-config”
Configure Backend Configuration:
apiVersion: cloud.google.com/v1
kind: BackendConfig
metadata:
name: my-backendconfig
spec:
timeoutSec: 40
BackendConfig to set a backend service timeout period in seconds.The following BackendConfig manifest specifies a timeout of 40 seconds.
Associate the backend configuration with service:
apiVersion: v1
kind: Service
metadata:
annotations:
cloud.google.com/backend-config: ‘{“ports”:{“my-backendconfig”}}’
cloud.google.com/neg: ‘{“ingress”: true}’
spec:
ports:
- name: app
port: 80
protocol: TCP
targetPort: 50000
We can specify a custom BackendConfig for one or more ports using a key that matches the port’s name or number. The Ingress controller uses the specific BackendConfig when it creates a load balancer backend service for a referenced Service port.
Creating an Ingress with a Google-Managed SSL Certificate
To set up a Google-managed SSL certificate and link it to an Ingress, follow these steps:
- Create a ManagedCertificate resource in the same namespace as the Ingress.
- Associate the ManagedCertificate with the Ingress by adding the annotation networking.gke.io/managed-certificates to the Ingress resource.
apiVersion: networking.gke.io/v1
kind: ManagedCertificate
metadata:
name: managed-cert
spec:
domains:
- hello.example.com
- world.example.com
Associate the SSL with Ingress
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress
annotations:
networking.gke.io/v1beta1.FrontendConfig: “my-frontend-config”
networking.gke.io/managed-certificates: managed-cert
kubernetes.io/ingress.class: “gce”
associate it with the managed-certificate by adding an annotation.
Assign Static IP to Ingress
When hosting a web server on a domain, the application’s external IP address should be static to ensure it remains unchanged.
By default, GKE assigns ephemeral external IP addresses for HTTP applications exposed via an Ingress. However, these addresses can change over time. If you intend to run your application long-term, it is essential to use a static external IP address for stability.
Create a global static ip from gcp console with specific name eg: web-static-ip and associate it with ingress by adding the global-static-ip-name annotation.
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress
annotations:
networking.gke.io/v1beta1.FrontendConfig: “my-frontend-config”
networking.gke.io/managed-certificates: managed-cert
kubernetes.io/ingress.class: “gce”
kubernetes.io/ingress.global-static-ip-name: “web-static-ip”
Google Cloud Armor Ingress security policy
Google Cloud Armor security policies safeguard your load-balanced applications against web-based attacks. Once configured, a security policy can be referenced in a BackendConfig to apply protection to specific backends.
To enable a security policy, add its name to the BackendConfig. The following example configures a security policy named security-policy:
apiVersion: cloud.google.com/v1
kind: BackendConfig
metadata:
namespace: cloud-armor-how-to
name: my-backendconfig
spec:
securityPolicy:
name: “security-policy”
User-defined request/response headers
A BackendConfig can be used to define custom request headers that the load balancer appends to requests before forwarding them to the backend services.
These custom headers are only added to client requests and not to health check probes. If a backend requires a specific header for authorization and it is absent in the health check request, the health check may fail.
To configure user-defined request headers, specify them under the customRequestHeaders/customResponseHeaders property in the BackendConfig resource. Each header should be defined as a header-name:header-value string.
apiVersion: cloud.google.com/v1
kind: BackendConfig
metadata:
name: my-backendconfig
spec:
customRequestHeaders:
headers:
- “X-Client-Region:{client_region}”
- “X-Client-City:{client_city}”
- “X-Client-CityLatLong:{client_city_lat_long}”
apiVersion: cloud.google.com/v1
kind: BackendConfig
metadata:
name: my-backendconfig
spec:
customResponseHeaders:
headers:
- “Strict-Transport-Security: max-age=28800; includeSubDomains”
The Ankercloud Team loves to listen